JUC
1.JUC概述
1.1JUC简介
在 Java 中,线程部分是一个重点,本篇文章说的 JUC 也是关于线程的。JUC 就是 java.util.concurrent 工具包的简称。这是一个处理线程的工具包,JDK 1.5 开始出现的。
1.2 进程与线程
进程(Process) 是指系统中运行的程序的实例。每个进程都是独立运行的,它们之间相互隔离,互不干扰。
线程(Thread)是进程中的一个执行单元。一个进程可以包含多个线程,这些线程共享进程的资源。线程是CPU调度和执行的基本单位。
1.3线程的状态
Java提供了Thread类和Runnable接口来创建和管理线程,线程的状态可以通过Thread类的getState()方法获取。
在Java中,线程的状态包括以下几种:
- 新建(NEW):线程对象被创建但还没有调用start()方法启动执行。
- 就绪(RUNNABLE):线程已经调用start()方法,等待系统的调度。
- 运行(RUNNING):线程正在执行任务。
- 阻塞(BLOCKED):线程被阻塞,等待获取锁或等待I/O完成等阻塞事件。
- 等待(WAITING):线程进入等待状态,等待其他线程的特定操作,如等待对象的notify()方法或wait()方法的调用。
- 超时等待(TIMED_WAITING):线程进入等待状态,但设置了最长等待时间,在达到指定时间或满足特定条件时自动唤醒。
- 终止(TERMINATED):线程执行完毕或发生异常,线程终止。
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
}1.4sleep()和wait()的区别
相同点:
- 一旦执行,都会使得当前线程结束执行状态,进入阻塞状态。
不同点:
- 定义方法所属的类:sleep():Thread中定义。 wait():Object中定义
- 使用范围的不同:sleep()可以在任何需要使用的位置被调用; wait():必须使用在同步代码块或同步方法中
- 都在同步结构中使用的时候,是否释放同步监视器:sleep():不会释放同步监视器 ;wait():会释放同步监视器
- 结束等待的方式不同:sleep():指定时间一到就结束阻塞。 wait():可以指定时间也可以无限等待直到notify或notifyAll。
1.5管程
管程(monitor)是一种用于实现线程同步的机制。Java中的synchronized关键字就是基于管程实现的。
在Java中,每个对象都可以看作是一个管程,通过使用synchronized关键字可以对对象的方法或代码块进行同步控制。当一个线程访问被synchronized修饰的方法或代码块时,它会自动获取该对象的锁,其他线程必须等待锁的释放才能继续执行。
使用管程可以解决多线程并发访问共享资源时可能出现的数据竞争、临界区问题等,并确保线程之间的顺序执行。
Java中使用管程的一种常见方式是使用synchronized关键字。可以在方法声明中添加synchronized关键字,也可以使用synchronized代码块来对关键代码片段进行同步控制。
1.6 用户线程和守护线程
在Java中,线程分为两种类型:用户线程(User Thread)和守护线程(Daemon Thread),它们在线程执行和程序结束时有一些不同的行为。
- 用户线程(User Thread):
- 默认情况下,所有的线程都是用户线程。
- 用户线程的执行不会影响程序的结束,即使所有的用户线程都执行完毕,程序仍然会继续执行直到主线程结束。
- 可以通过创建Thread对象并启动线程来创建用户线程。
- 守护线程(Daemon Thread):
- 守护线程是一种特殊类型的线程,它的存在依赖于其他非守护线程。
- 当所有的用户线程都执行完毕后,守护线程会随之自动结束,无需等待。
- 守护线程通常被用于执行一些后台任务,如垃圾回收(Garbage Collection)。
- 可以通过调用Thread对象的
setDaemon(true)方法将线程设置为守护线程,或者使用线程组(ThreadGroup)的setDaemon(true)方法设置该组中的线程为守护线程。setDaemon(true)必须在thread.start()之前设置。
1.7并发和并行
并发(Concurrency)是指多个任务交替执行的能力。在并发模型中,多个任务可以在同一时间段内执行,但不一定是同时执行。这是通过任务切换的方式实现的,即任务按照一定的调度策略轮流执行一段时间,然后暂停,切换到另一个任务执行。
并行(Parallelism)是指多个任务同时执行的能力。在并行模型中,多个任务可以在同一时刻同时执行,可以利用多核处理器或分布式系统来实现任务并行执行。
2.线程间通信
2.1线程间通信概述
线程间通信(Inter-thread communication)是指在多线程编程中,不同线程之间共享信息、传递数据或进行协调的过程。
即多个线程在并发执行的时候,他们在CPU中是随机切换执行的,这个时候我们想多个线程一起来完成一件任务,这个时候我们就需要线程之间的通信了,多个线程一起来完成一个任务。
2.2线程间通信的方式
- 通过 volatile 关键字
- 通过 Object类的 wait/notify 方法
- 通过 Condition 的 await/signal 方法
volatile 是**共享内存**的,两个线程共享一个标志位,当标志位更改的时候就执行不同的线程。
Object类提供了三个线程间通信的方法,wait(),notify(),notifyAll()。这三个方法必须都在同步代码块中执行的。
| 方法名 | 具体操作 |
|---|---|
| wait() | wait()方法执行前,是必须要获得对应的锁的,当执行wait()方法后,线程就会释放掉自己所占有的锁,释放CPU,然后进入阻塞状态,直到被notify()方法唤醒。对于某一个参数的版本,实现中断和虚假唤醒是可能的,而且此方法应始终在循环中使用: |
| notify() | 会唤醒一个处于等待该对象锁的线程,然后继续往下执行,直到执行完退出对象锁锁住的区域(synchronized修饰的代码块)后再释放锁。 |
| notifyAll() | 和notify()方法差不多,只不过他是唤醒所有等待该对象锁的线程,让他们进入就绪队列,但是谁执行就看谁抢占到CPU,notify()方法也是这样,只不过是唤醒随机的一个而已 |
- Condiction对象是通过
lock对象来创建得(调用lock对象的newCondition()方法),他在使用前也是需要获取锁得,其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。Condiction对象得常用方法:
- await() : 线程自主释放锁,进入沉睡状态,直到被再次唤醒。
- await(long time, TimeUnit unit) :线程自主释放锁,进入沉睡状态,被唤醒或者未到达等待时间时一直处于等待状态。
- signal(): 唤醒一个等待线程。
- signal()All() :唤醒所有等待线程,能够从等待方法返回的线程必须获得与Condition相关的锁。
2.3synchronized实现线程间通信
采用通过匿名内部类的方式来实现Runnable接口创建多线程。采用synchronized关键字来实现同步方法。通过 Object类的 wait/notify 方法来实现线程间通信。
Oprea类:
class Oprea{
private int number = 0;
public synchronized void add() throws InterruptedException {
while (number != 0){
this.wait();
}
number++;
System.out.println(Thread.currentThread().getName() + "::" + number);
this.notifyAll();
}
public synchronized void minus() throws InterruptedException {
while (number == 0){
this.wait();
}
number--;
System.out.println(Thread.currentThread().getName() + "::" + number);
this.notifyAll();
}
}ThreadCommouication类:
public class ThreadCommouication {
public static void main(String[] args) {
Oprea oprea = new Oprea();
new Thread(() -> {
for (int i = 0; i < 5; i++) {
try {
oprea.add();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
},"线程01").start();
new Thread(() -> {
for (int i = 0; i < 5; i++) {
try {
oprea.minus();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
},"线程02").start();
}
}

2.3Lock实现线程间通信
采用通过匿名内部类的方式来实现Runnable接口创建多线程。采用Lock接口的实现类ReentrantLock来实现线程间互斥。通过 Condition 的 await/signalAll 方法来实现线程间通信。
Oprea类:
class Oprea {
private int number = 0;
private ReentrantLock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public void add(){
lock.lock();
try {
while (number != 0) {
condition.await();
}
number++;
System.out.println(Thread.currentThread().getName() + "::" + number);
condition.signalAll();
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
public void minus() {
lock.lock();
try {
while (number == 0) {
condition.await();
}
number--;
System.out.println(Thread.currentThread().getName() + "::" + number);
condition.signalAll();
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
}ThreadCommouication类:
public class ThreadCommunication {
public static void main(String[] args) {
Oprea oprea = new Oprea();
new Thread(() -> {
for (int i = 0; i < 5; i++) {
oprea.add();
}
}, "线程01").start();
new Thread(() -> {
for (int i = 0; i < 5; i++) {
oprea.minus();
}
}, "线程02").start();
}
}
3.集合的线程安全
3.1Java中线程安全的集合
3.1.1早期线程安全集合
集合中线程安全的类都是jdk1.1中的出现的。
- Vector:就比
arraylist多了个同步化机制(线程安全),因为效率较低,现在已经不太建议使用- Statck:堆栈类,先进后出
- Hashtable:就比hashmap多了个线程安全
- Enumeration:枚举,相当于迭代器
3.1.2Collections包装方法
Vector和HashTable被弃用后,它们被ArrayList和HashMap代替,但它们不是线程安全的,所以Collections工具类中提供了相应的包装方法把它们包装成线程安全的集合
List<E> synArrayList = Collections.synchronizedList(new ArrayList<E>());
Set<E> synHashSet = Collections.synchronizedSet(new HashSet<E>());
Map<K,V> synHashMap = Collections.synchronizedMap(new HashMap<K,V>());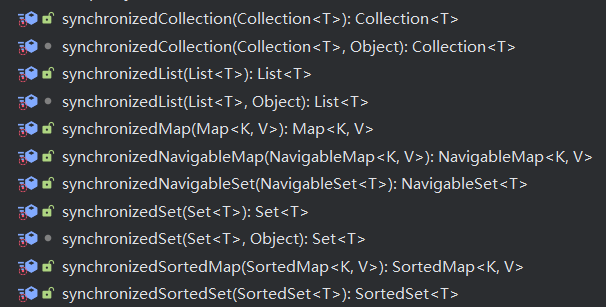
Collections针对每种集合都声明了一个线程安全的包装类,在原集合的基础上添加了锁对象,集合中的每个方法都通过这个锁对象实现同步
3.1.3java.util.concurrent包中的集合
在Java中,java.util.concurrent包提供了一些线程安全的集合类,这些类是为了在多线程环境下提供高效且线程安全的操作而设计的。以下是其中一些常用的线程安全集合类:
ConcurrentHashMap:是为了解决HashMap线程不安全问题。这是一个线程安全的哈希表实现,支持高并发读写操作,采用分段锁机制,不同的线程可以同时访问不同的分段,提高了并发性能。CopyOnWriteArrayList:是为了解决ArrayList线程不安全问题。这是一个线程安全的动态数组实现,在写操作时会创建一个原数组的副本,从而避免了读写冲突,读操作可以在不加锁的情况下并发进行。ConcurrentLinkedQueue:是为了解决LinkedList线程不安全问题。这是一个非阻塞的无界队列实现,适用于高并发场景下的生产者和消费者模式,提供了高效的并发插入和删除操作。ConcurrentSkipListMap:是为了解决TreeMap线程不安全问题。这是一个基于跳表实现的有序映射表,支持高并发读写操作,具有良好的并发性能。ConcurrentSkipListSet:是为了解决TreeSet线程不安全问题。这是一个基于跳表实现的有序集合,支持高并发读写操作,也具有良好的并发性能。ConcurrentLinkedDeque:这是一个双端队列的实现,支持高并发的插入和删除操作,同时可以作为栈或队列使用。BlockingQueue:这是一个阻塞队列接口,用于实现生产者和消费者模式的线程安全队列,常用的实现类有ArrayBlockingQueue、LinkedBlockingQueue等。 8.Deque:这是一个阻塞双端队列接口,同时支持在队列的两端进行插入和删除操作,常用的实现类有LinkedBlockingDeque`。
这些线程安全集合类提供了可靠的线程安全性,并具有较好的并发性能。在多线程环境下,推荐使用这些线程安全集合类来保证数据的一致性和可靠性。
3.2集合线程不安全演示
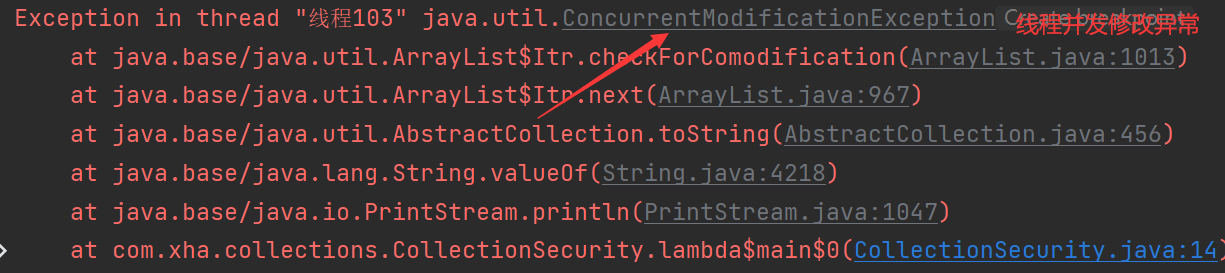
下面以线程不安全集合List接口的实现类ArrayList集合来演示集合不安全问题:
public class CollectionSecurity {
public static void main(String[] args) {
ArrayList<String> strs = new ArrayList<>();
// 产生并发修改异常
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
strs.add(UUID.randomUUID().toString().substring(0,10));
System.out.println(strs);
}, "线程" + i).start();
}
}
}
异常信息如下:产生ConcurrentModificationException并发修改异常。
3.3集合线程不安全解决方案
3.3.1使用线程安全的集合
public class CollectionSecurity {
public static void main(String[] args) {
Vector<String> strs = new Vector<>();
// 产生并发修改异常
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
strs.add(UUID.randomUUID().toString().substring(0, 10));
System.out.println(strs);
}, "线程" + i).start();
}
}
}但是因为Vector通过使用synchronized关键字来保证线程安全性,这意味着在对Vector进行并发操作时,需要获取和释放锁。这种锁的机制会引入一定的同步开销,影响性能。
3.3.2使用Collections包装方法
public class CollectionSecurity {
public static void main(String[] args) {
List<Object> strs = Collections.synchronizedList(new ArrayList<>());
// 产生并发修改异常
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
strs.add(UUID.randomUUID().toString().substring(0, 10));
System.out.println(strs);
}, "线程" + i).start();
}
}
}3.3.3使用java.util.concurrent包中的集合
public class CollectionSecurity {
public static void main(String[] args) {
CopyOnWriteArrayList<Object> strs = new CopyOnWriteArrayList<>();
// 产生并发修改异常
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
strs.add(UUID.randomUUID().toString().substring(0, 10));
System.out.println(strs);
}, "线程" + i).start();
}
}
}4.多线程锁
4.1synchronized锁
4.1.1synchronized概述
对于synchronized的同步锁:
synchronized(同步锁){
需要同步操作的代码
}synchronized 是 Java 中的关键字,是一种同步锁。它修饰的对象有以下几种:
- 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{} 括起来的代码,作用的对象是调用这个代码块的对象;
- 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
- 虽然可以使用 synchronized 来定义方法,但 synchronized 并不属于方法定义的一部分,因此,synchronized 关键字不能被继承。如果在父类中的某个方法使用了 synchronized 关键字,而在子类中覆盖了这个方法,在子类中的这个方法默认情况下并不是同步的,而必须显式地在子类的这个方法中加上 synchronized 关键字才可以。
- 当然,还可以在子类方法中调用父类中相应的方法,这样虽然子类中的方法不是同步的,但子类调用了父类的同步方法,因此, 子类的方法也就相当于同步了。
- 修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
- 修改一个类,其作用的范围是 synchronized 后面括号括起来的部分,作用的对象是这个类的所有对象。
同步锁对象可以是任意对象类型,但是必须保证竞争“同一个共享资源”的多个线程必须使用同一个“同步锁对象”。
对于同步代码块来说,同步锁对象是由程序员手动指定的(很多时候也是指定为this或类名.class),但是对于同步方法来说,同步锁对象只能是默认的:
- 静态方法:当前类的Class对象(类名.class)
- 非静态方法:this
为什么不建议使用this作为锁对象
从语法上来讲,可以使用this作为同步代码块的同步锁,也可以使用其他对象作为参数。 但是,使用this的方式可能会导致一些问题。
如果在一个类中,既有同步方法,又有同步代码块,并且同步代码块使用的是this对象作为锁,那么同步方法和同步代码块将同时争夺this对象的锁,这可能会导致死锁问题。
为了避免这些问题,建议使用专门的对象作为锁,而不是使用this。 例如,可以创建一个私有对象来充当锁,然后在需要同步的代码块中使用该锁。 这将避免锁竞争和死锁问题,保证程序正确、高效地运行。
4.1.2案例演示Synchronized同步锁
本案例采用匿名方式实现Runnable接口的方式来创建多线程:
Ticket类:
class Ticket {
private int number = 30;
public synchronized void sale() {
if (number > 0) {
System.out.println(Thread.currentThread().getName() + "卖出票:" + (number--) + ",剩余" + number + "张。");
}
}
}SaleTicket类:
public class SaleTicket {
public static void main(String[] args) {
Ticket ticket = new Ticket();
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 40; i++) {
ticket.sale();
}
}
},"线程01").start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 40; i++) {
ticket.sale();
}
}
},"线程02").start();
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 40; i++) {
ticket.sale();
}
}
},"线程03").start();
}
}测试结果:

4.1.4synchronized锁的6种情况
关于
synchronized锁的几种情况,归结原因全都是因为锁对象不同。要分清对象锁和类锁。
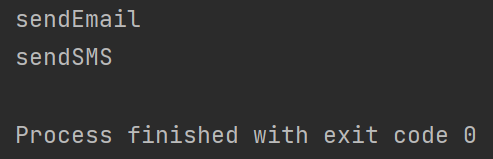
- 情况1:两个同步方法,查看打印情况
两个方法都添加synchronized关键字,同时在main方法种使用的是Phone类的同一个实例,那么就是使用的对象锁,当一个线程获取到锁后,其他线程都不能再获取锁,直至第一个线程将锁释放。
class Phone {
public synchronized void sendEmail() {
System.out.println("sendEmail");
}
public synchronized void sendSMS() {
System.out.println("sendSMS");
}
}
public class PhoneDemo {
public static void main(String[] args) {
Phone phone = new Phone();
new Thread(() -> {
phone.sendEmail();
}, "A").start();
new Thread(() -> {
phone.sendSMS();
}, "B").start();
}
}输出结果:
- 情况2:为了验证情况1当中的对象锁,阻塞
SendEmail方法,查看打印情况。
class Phone {
public synchronized void sendEmail() {
try {
// 阻塞2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("sendEmail");
}
public synchronized void sendSMS() {
System.out.println("sendSMS");
}
}
public class PhoneDemo {
public static void main(String[] args) {
Phone phone = new Phone();
new Thread(() -> {
phone.sendEmail();
}, "A").start();
new Thread(() -> {
phone.sendSMS();
}, "B").start();
}
}
- 情况3:添加一个普通方法,查看是先打印邮件还是普通方法
普通方法不会受synchronized锁的影响。
class Phone {
public synchronized void sendEmail() {
try {
// 阻塞2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("sendEmail");
}
public synchronized void sendSMS() {
System.out.println("sendSMS");
}
public void commonMethod() {
System.out.println("commonMethod");
}
}
public class PhoneDemo {
public static void main(String[] args) {
Phone phone = new Phone();
new Thread(() -> {
phone.sendEmail();
}, "A").start();
new Thread(() -> {
phone.commonMethod();
}, "B").start();
}
}
- 情况4:创建两个Phone实例,查看打印顺序。
创建两个Phone实例,所以是两把不同的对象锁。当处于不同的锁,另一个线程也能调用。
class Phone {
public synchronized void sendEmail() {
try {
// 阻塞2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("sendEmail");
}
public synchronized void sendSMS() {
System.out.println("sendSMS");
}
}
public class PhoneDemo {
public static void main(String[] args) {
Phone phone1 = new Phone();
Phone phone2 = new Phone();
new Thread(() -> {
phone1.sendEmail();
}, "A").start();
new Thread(() -> {
phone2.sendSMS();
}, "B").start();
}
}
- 情况5:两个静态同步方法,查看打印顺序
两个静态同步方法,使用的同一个锁,及类锁
class Phone {
public static synchronized void sendEmail() {
try {
// 阻塞2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("sendEmail");
}
public static synchronized void sendSMS() {
System.out.println("sendSMS");
}
public void commonMethod() {
System.out.println("commonMethod");
}
}
public class PhoneDemo {
public static void main(String[] args) {
new Thread(() -> {
Phone.sendEmail();
}, "A").start();
new Thread(() -> {
Phone.sendSMS();
}, "B").start();
}
}
- 情况6:一个静态同步方法,一个普通同步方法,查看打印顺序
一个静态同步方法,使用的是类锁。一个普通同步方法,使用的对象锁。使用的锁不同
class Phone {
public static synchronized void sendEmail() {
try {
// 阻塞2秒
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("sendEmail");
}
public synchronized void sendSMS() {
System.out.println("sendSMS");
}
}
public class PhoneDemo {
public static void main(String[] args) {
Phone phone = new Phone();
new Thread(() -> {
Phone.sendEmail();
}, "A").start();
new Thread(() -> {
phone.sendSMS();
}, "B").start();
}
}
4.1.5synchronized字节码分析
4.1.5.1synchronized同步代码块
对于以下代码块,查看其字节码
public class ClassAnalyseDemo {
public void method(){
synchronized (this){
System.out.println("hello");
}
}
}查看字节码,实现使用的是monitorenter和monitorexit指令
存在两个monitorexit的原因是为了确保在发生异常时,能够正确地释放对象的监视器锁,从而避免死锁
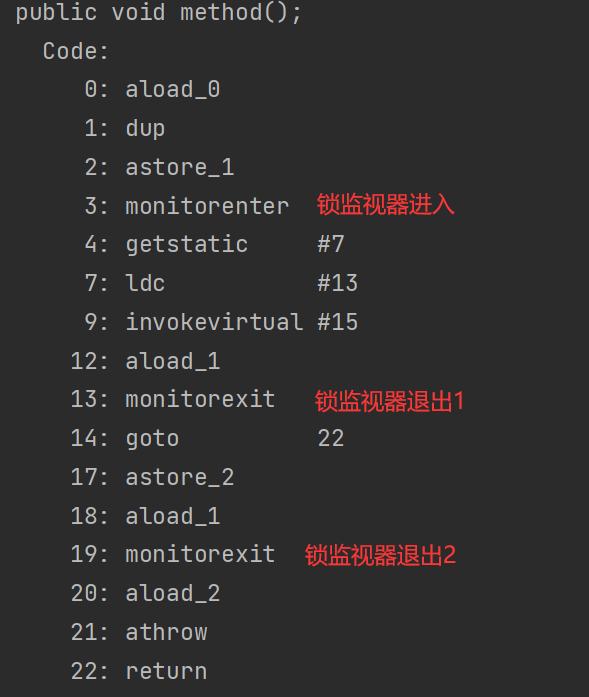
4.1.5.2synchronized同步方法
对于以下方法,查看其字节码文件:
public class ClassAnalyseDemo {
public synchronized void method(){
System.out.println("method");
}
}- 调用指令将会检查方法的
ACC_SYNCHRONIZED访问标志是否被设置,如果设置了,执行线程会将现持有monitor锁,然后再执行该方法,最后在方法完成(无论是否正常结束)时释放monitor
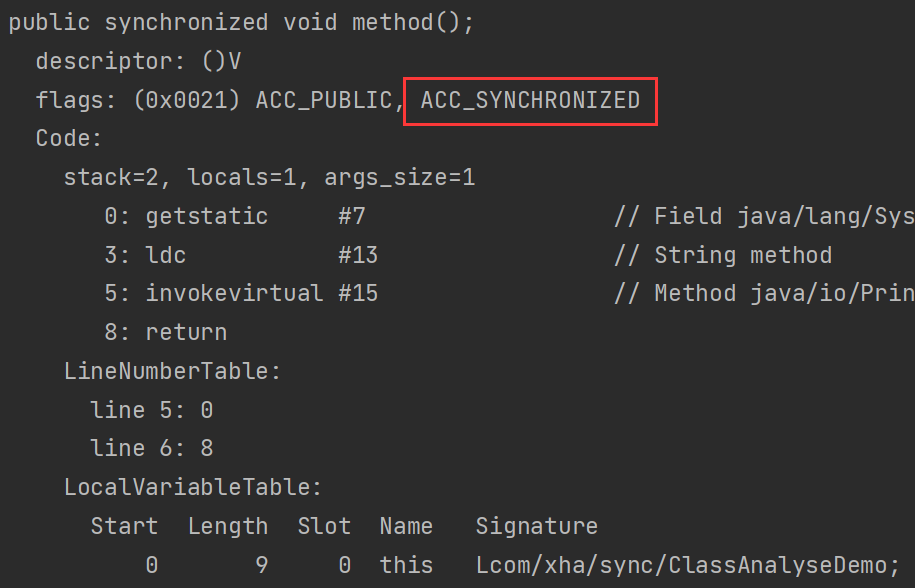
4.1.5.3synchronized静态同步方法
对于以下方法,查看其字节码文件:
public class ClassAnalyseDemo {
public static synchronized void method(){
System.out.println("method");
}
}ACC_STATIC、ACC_SYNCHRONIZED访问标志区分该方法是否是静态同步方法

4.1.6为什么每个对象都可以作为锁
每一个对象都可以作为锁的原因在于,Java中的每个对象都与一个监视器关联。
在Java中,每个对象都有一个与之关联的监视器。当一个线程需要访问一个对象的同步代码块时,它会尝试获取该对象的监视器锁。如果该锁已被其他线程持有,那么线程将被阻塞,直到锁被释放。
由于每个对象都具有与之关联的监视器,因此每个对象都可以被用作锁。锁是独立于对象实例的,而是与对象的特定实例相关联的。这意味着,即使存在多个对象的实例,每个实例都有自己的锁。这样,不同的线程可以以并发的方式访问不同的对象实例。
其中每个对象头当中含有锁状态标识,用于表示对象的锁定状态。
4.2Lock
4.2.1Lock锁概述
Lock锁又被称为显示锁。Lock锁可以实现更灵活的线程同步和互斥操作。Lock 提供了比 synchronized 更多的功能。
4.2.2Lock接口概述
Lock锁是指通过Lock接口的实现类,例如ReentrantLock,来实现对线程同步和互斥访问的机制。Lock接口定义了一组方法,用于获取锁、释放锁以及其他一些与锁相关的操作。
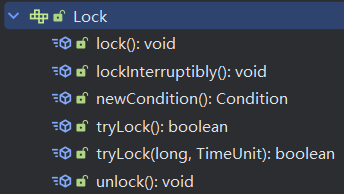
- **lock()**:获得锁,如果锁不可用,则当前线程被阻塞,直到锁可用。
- **unlock()**:释放锁,将锁状态恢复为可用。
- **tryLock()**:尝试获取锁,如果锁可用,则立即获得锁并返回true,否则返回false。
- **tryLock(long time, TimeUnit unit)**:在指定的时间内尝试获取锁,如果在指定时间内获取到锁,则返回true,否则返回false。
- **lockInterruptibly()**:如果当前线程未被中断,则获取锁。
- **Condition newCondition()**:返回绑定到此 Lock 实例的新
Condition实例
Lock接口的实现类如下:

ReentrantLock:可重入锁,是最常用的实现类。它提供了与Synchronized关键字类似的功能,但更加灵活和可控。ReentrantReadWriteLock:可重入读写锁,适用于读多写少的场景。它提供了读锁和写锁的机制,可以实现多个线程同时读取数据,但只允许一个线程写入数据。
4.2.2Lock和Synchronized的区别
Lock和Synchronized都是用于实现线程同步的机制,但有一些区别:
- 关键字:Synchronized是Java中的关键字,可以直接在方法声明或代码块中使用。而Lock是一个接口,需要使用Lock的实现类来创建对象,并通过调用Lock对象的方法来实现同步。
- 灵活性:Synchronized是隐式锁,当线程执行完Synchronized代码块或方法后会自动释放锁。而Lock时显示锁,需要手动调用lock()方法获得锁,并在使用完资源后调用unlock()方法释放锁,灵活性更高。
- 可中断性:在使用Lock时,可以通过调用
lockInterruptibly()方法来实现可中断的锁获取,即当线程在等待锁时,如果被其他线程中断,可以选择直接放弃获取锁。而Synchronized的获取锁是不可中断的。- 性能:在高并发的情况下,Lock的性能可能比Synchronized更好,因为Synchronized是基于JVM实现的,而Lock是通过代码实现的。
总的来说,Lock相比Synchronized更灵活,可中断性更好,并且支持条件锁。但在普通的线程同步场景中,Synchronized已经足够简单和方便,而且性能表现也优秀,所以在大多数情况下,Synchronized是首选的。
4.2.3案例演示Lock锁
Ticket类:
class Ticket {
private int number = 30;
private final ReentrantLock lock = new ReentrantLock();
public void sale() {
// 1.上锁
lock.lock();
try {
if (number > 0) {
System.out.println(Thread.currentThread().getName() + "卖出票:" + (number--) + ",剩余" + number + "张。");
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
// 2.解锁
lock.unlock();
}
}
}SaleTicket类:
public class SaleTicket {
public static void main(String[] args) {
Ticket ticket = new Ticket();
new Thread(() -> {
for (int i = 0; i < 40; i++) {
ticket.sale();
}
}, "线程01").start();
new Thread(() -> {
for (int i = 0; i < 40; i++) {
ticket.sale();
}
}, "线程02").start();
new Thread(() -> {
for (int i = 0; i < 40; i++) {
ticket.sale();
}
}, "线程03").start();
}
}测试结果:
4.3公平锁和非公平锁
公平锁:
公平锁保证线程按照请求的顺序获取锁。当多个线程同时请求获取锁时,公平锁会维护一个等待队列,新到来的线程会排队等待,先请求的线程先获取锁。公平锁的优点是保证了锁的公平性,避免了饥饿现象(即某个线程一直无法获取锁),但它可能会导致线程切换的开销增加,降低了并发性能。
非公平锁:
非公平锁允许新请求的线程比等待队列中的线程优先获取锁。当一个线程释放锁时,不一定是等待时间最长的线程获取锁,而是新到来的线程有机会直接获取锁。非公平锁的优点是减少了线程切换的开销,提高了并发性能,但它可能导致等待时间长的线程一直无法获取锁,存在不公平性。
无论是公平锁还是非公平锁,它们的实现机制都是基于同步器(如ReentrantLock、synchronized等)。在使用锁时,可以根据具体的应用场景来选择合适的锁类型。如果希望保证线程请求锁的公平性,可以选择公平锁。如果追求更高的并发性能,可以选择非公平锁。
- 查看
ReentrantLock源码,查看其无参构造:
public ReentrantLock() {
sync = new NonfairSync();
}及其默认使用的是非公平锁。
- 查看有参构造
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}该有参构造接收一个boolean的参数,当参数为true的时候为公平锁,为false的时候为非公平锁。
- 案例
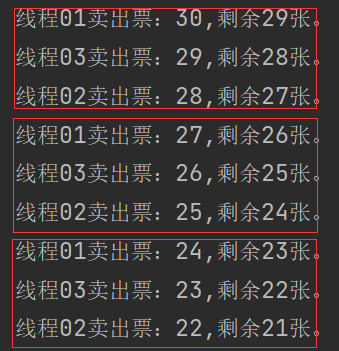
基于ReentrantLock实现公平锁
Ticket类:
class Ticket {
private int number = 30;
private final ReentrantLock lock = new ReentrantLock(true);
public void sale() {
// 1.上锁
lock.lock();
try {
if (number > 0) {
System.out.println(Thread.currentThread().getName() + "卖出票:" + (number--) + ",剩余" + number + "张。");
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
// 2.解锁
lock.unlock();
}
}
}SaleTicket类:
public class SaleTicket {
public static void main(String[] args) {
Ticket ticket = new Ticket();
Thread thread01 = new Thread(() -> {
for (int i = 0; i < 40; i++) {
ticket.sale();
}
}, "线程01");
Thread thread02 = new Thread(() -> {
for (int i = 0; i < 40; i++) {
ticket.sale();
}
}, "线程02");
Thread thread03 = new Thread(() -> {
for (int i = 0; i < 40; i++) {
ticket.sale();
}
}, "线程03");
thread01.start();
thread02.start();
thread03.start();
try {
thread01.join();
thread02.join();
thread03.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}测试结果:
4.4可重入锁
可重入锁是一种特殊的锁机制,也称为递归锁。它允许线程在持有锁的情况下多次进入同一个临界区域,而不会造成死锁或其他异常情况。
可重入锁的特点如下:
- 同一个线程可以重复获取同一个锁,不会造成死锁。当线程第一次获取锁后,锁的计数器会加1,线程可以多次获取锁而不受阻塞,并在最后一次释放锁后完全释放。
- 可重入锁提供了简单直观的编程模型。在复杂的嵌套代码块中,可以避免手动管理锁的释放和获取操作,只需要在最外层获取锁,然后在内层递归调用时仍然可以获取该锁。
- 可重入锁保证了线程在持有锁的情况下对临界区的原子性操作,避免了资源竞争问题。
在Java中,可重入锁的实现有多种,其中sychronized和Lock都是可重入锁。最常见的是通过ReentrantLock类来实现。它提供了与synchronized相似的功能,但具有更高的灵活性和可扩展性。通过使用可重入锁,可以确保线程安全的同时,避免了死锁和其他同步问题。
案例:
public class ReenTrantLockTest {
private static final ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {
// 创建多个线程
Thread thread01 = new Thread(new Worker());
Thread thread02 = new Thread(new Worker());
// 启动线程
thread01.start();
thread02.start();
// 等待子线程执行完成才执行主线程
try {
thread01.join();
thread02.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
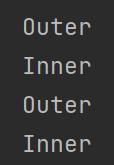
static class Worker implements Runnable {
@Override
public void run() {
lock.lock();
try {
System.out.println("Outer");
recursiveMethod();
} finally {
lock.unlock();
}
}
/**
* 递归方法
*/
private void recursiveMethod() {
lock.lock();
try {
System.out.println("Inner");
} finally {
lock.unlock();
}
}
}
}测试结果:
4.5读写锁
4.5.1读写锁的概念
读写锁,也称为共享-独占锁,是一种用于控制对共享资源的访问的锁机制。它允许多个线程同时读取共享资源,但只允许一个线程进行写操作。
读写锁具有两种状态:读取状态和写入状态。
- 当没有线程进行写操作时,多个线程可以同时获取读锁并读取共享资源。这种方式可以提高并发性能,因为多个读操作不会相互干扰。
- 当有线程进行写操作时,写锁会被独占,此时不允许其他线程获取读锁或写锁。这是为了确保数据的一致性和完整性,避免并发操作对数据造成干扰或冲突。
读写锁通常适用于读操作频繁且不修改共享资源的场景,以提高并发性能。但需要注意的是,如果写操作过于频繁,可能会导致读操作的性能下降,因为每次写操作都需要独占访问资源。
4.5.2ReentrantReadWriteLock
JUC(Java Util Concurrent)提供了ReentrantReadWriteLock类,它是一个可重入的读写锁。读写锁允许多个线程同时读取共享资源,但只允许一个线程写入共享资源。这种锁的特性使得读写操作可以更高效地并发进行。
ReentrantReadWriteLock实现了ReadWriteLock接口,它提供了以下方法:
readLock():返回一个读锁,允许多个线程同时持有读锁并进行读取操作。writeLock():返回一个写锁,只允许一个线程持有写锁进行写入操作。readLock().lock():获取读锁,如果有其他线程已经持有写锁,则阻塞当前线程。writeLock().lock():获取写锁,如果有其他线程已经持有读锁或写锁,则阻塞当前线程。readLock().unlock():释放读锁。writeLock().unlock():释放写锁。
未添加读写锁的时候测试
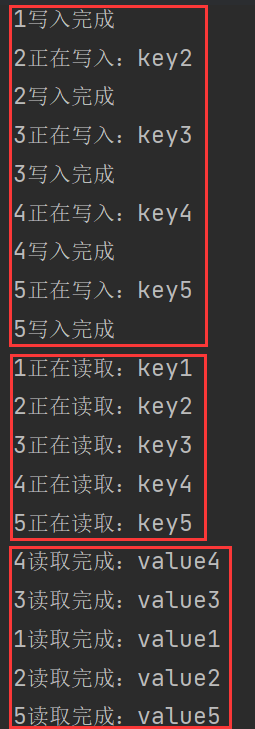
import java.util.HashMap;
import java.util.Map;
class OpreationData{
private volatile Map<String,String> map = new HashMap<>();
// 写操作
public void put(String key,String value){
System.out.println(Thread.currentThread().getName()+"正在写入:"+key);
try {
Thread.sleep(300);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
map.put(key,value);
System.out.println(Thread.currentThread().getName()+"写入完成");
}
// 读操作
public void get(String key){
System.out.println(Thread.currentThread().getName()+"正在读取:"+key);
try {
Thread.sleep(300);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
String result = map.get(key);
System.out.println(Thread.currentThread().getName()+"读取完成:"+result);
}
}
public class ReadWriteLockDemo {
public static void main(String[] args) {
OpreationData opreationData = new OpreationData();
for (int i = 1; i <= 5; i++) {
final int tempInt = i;
new Thread(() -> {
opreationData.put("key" + tempInt,"value" + tempInt);
},String.valueOf(i)).start();
}
for (int i = 1; i <= 5; i++) {
final int tempInt = i;
new Thread(() -> {
opreationData.get("key" + tempInt);
},String.valueOf(i)).start();
}
}
}测试结果:

添加读写锁:
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
class OpreationData{
private volatile Map<String,String> map = new HashMap<>();
ReadWriteLock rwLock = new ReentrantReadWriteLock();
// 写操作
public void put(String key,String value){
rwLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName()+"正在写入:"+key);
try {
Thread.sleep(300);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
map.put(key,value);
System.out.println(Thread.currentThread().getName()+"写入完成");
} finally {
rwLock.writeLock().unlock();
}
}
// 读操作
public void get(String key){
rwLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName()+"正在读取:"+key);
try {
Thread.sleep(300);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
String result = map.get(key);
System.out.println(Thread.currentThread().getName()+"读取完成:"+result);
} finally {
rwLock.readLock().unlock();
}
}
}
public class ReadWriteLockDemo {
public static void main(String[] args) {
OpreationData opreationData = new OpreationData();
for (int i = 1; i <= 5; i++) {
final int tempInt = i;
new Thread(() -> {
opreationData.put("key" + tempInt,"value" + tempInt);
},String.valueOf(i)).start();
}
for (int i = 1; i <= 5; i++) {
final int tempInt = i;
new Thread(() -> {
opreationData.get("key" + tempInt);
},String.valueOf(i)).start();
}
}
}
4.5.3锁降级
锁降级是指将一个线程持有的写锁转换为读锁的过程。通常情况下,写锁是独占的,只能由一个线程持有,并且其他线程无法读取或写入共享资源。但是在某些情况下,当一个线程已经持有写锁时,有时可以将写锁降级为读锁,允许其他线程同时读取资源,同时保持原有线程对资源的访问。
锁降级的过程通常包括以下步骤:
- 获取写锁:线程先获取写锁,确保自己独占资源。
- 获取读锁:然后线程再获取读锁,此时其他线程也可以获得读锁,允许并发读取共享资源。
- 释放写锁:最后,线程释放写锁。
- 释放读锁:在确保不再需要对资源进行修改或操作时,线程释放读锁。
锁降级的优点是可以提高并发性和降低锁的竞争,因为在降级后允许其他线程同时读取共享资源,而不需要等待写锁的释放。
4.6悲观锁和乐观锁
悲观锁和乐观锁是并发控制的两种不同策略,用于解决多线程环境中的数据竞争和数据一致性问题。
- 悲观锁(Pessimistic Locking): 悲观锁是一种保守的并发控制策略,它假设在任意时刻会发生冲突。为了避免冲突,悲观锁会在访问共享资源之前,将其加锁,并确保在整个操作过程中没有其他线程可以修改或读取这个共享资源。悲观锁的一个常见实现是使用互斥锁(如
synchronized关键字或Lock接口的实现类)来保护共享资源。- 乐观锁(Optimistic Locking): 乐观锁是一种更加乐观的并发控制策略,它假设在大部分情况下不会发生冲突,因此不会进行加锁操作,而是在更新共享资源时进行一次检查。乐观锁并不直接加锁,而是在读取共享资源时,记录下读取的版本号或时间戳等信息,在更新共享资源之前再次检查这些信息是否被其他线程修改过。如果没有发生冲突,更新操作继续进行;如果发生冲突,可能需要重试或执行其他处理策略。乐观锁常用的实现方式是使用
版本号或时间戳等机制来管理并检查资源的变化情况。
悲观锁适用于对共享资源的修改比较频繁的场景,它将资源的访问权限限制在某一时刻只能由一个线程独占,从而避免了并发冲突。然而,悲观锁会引入锁的开销,在高并发环境下可能造成性能瓶颈。
乐观锁适用于对共享资源的读取操作比较频繁,而对共享资源的修改冲突较少的场景。它通过尽量减少锁的使用,提高并发性能。然而,乐观锁需要检查共享资源是否被修改过,如果冲突较多,可能需要进行多次重试,影响效率。
4.6死锁
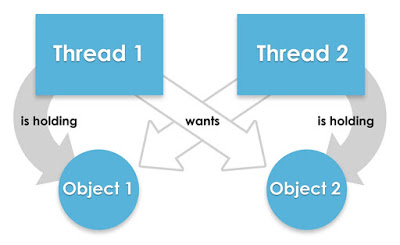
4.6.1什么是死锁
死锁就是不同的线程分别占用对方所需的资源不释放,并且都在等待对方首先释放自己所需要的资源,这就形成了死锁。
4.6.2产生死锁的条件
- 互斥条件:多个进程或线程竞争同一个资源,而这个资源一次只能被一个进程或线程占用。
- 请求与保持条件:一个进程或线程在持有某些资源的同时,又请求另外一些资源。如果这个请求无法满足,那么该进程或线程可能会一直等待,占用的资源也无法被其他进程或线程释放。
- 不可抢占条件:一旦进程或线程获得了某些关键资源,在没有完成使用这些资源之前,其他进程或线程不能强制抢占这些资源。
- 循环等待条件:多个进程或线程形成一个等待循环,每个进程或线程都在等待下一个进程或线程所持有的资源。
4.6.3死锁案例
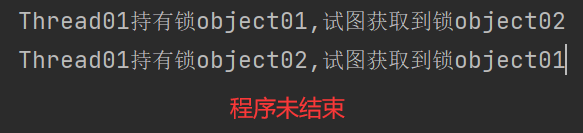
下面的代码是一个典型的死锁示例。代码中有两个线程(Thread01和Thread02),它们分别尝试获取object01和object02两个对象的锁。
在Thread01中,线程首先获取了object01对象的锁,然后试图获取object02对象的锁。在Thread02中,线程首先获取了object02对象的锁,然后试图获取object01对象的锁。
如果这两个线程同时运行,可能会出现以下情况:
- Thread01先获取到object01的锁,然后进入等待获取object02的锁;
- Thread02先获取到object02的锁,然后进入等待获取object01的锁。
这样,Thread01和Thread02之间形成了相互等待对方持有的锁的状态,造成了死锁。由于两个线程相互等待对方释放锁,导致两个线程都无法继续执行。
public class DeadLock {
static Object object01 = new Object();
static Object object02 = new Object();
public static void main(String[] args) {
Thread thread01 = new Thread(() -> {
synchronized (object01) {
System.out.println(Thread.currentThread().getName() + "持有锁object01,试图获取到锁object02");
synchronized (object02) {
System.out.println("获取到锁object02");
}
}
}, "Thread01");
Thread thread02 = new Thread(() -> {
synchronized (object02) {
System.out.println(Thread.currentThread().getName() + "持有锁object02,试图获取到锁object01");
synchronized (object01) {
System.out.println("获取到锁object01");
}
}
}, "Thread01");
thread01.start();
thread02.start();
try {
thread01.join();
thread02.join();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
在Java进程方面查看是否产生死锁:
使用jps命令查看当前类的进程号:
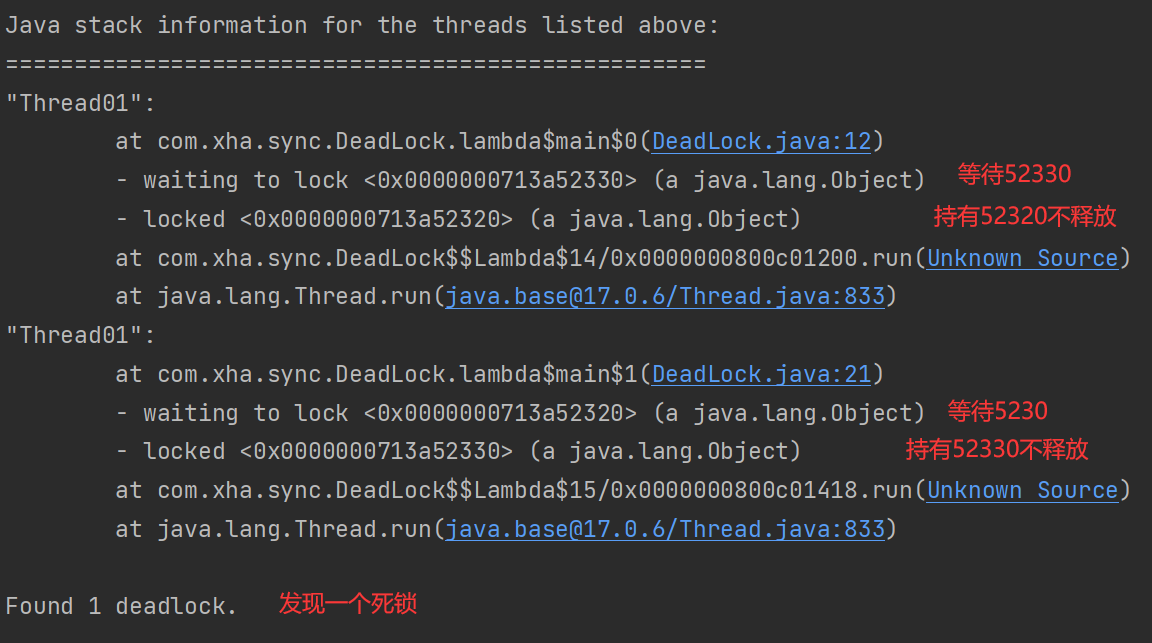
使用jstack命令查看当前类的线程状况和问题:
5.JUC辅助类
JUC 中提供了三种常用的辅助类,通过这些辅助类可以很好的解决线程数量过多时 Lock 锁的频繁操作。这三种辅助类为:
- CountDownLatch: 减少计数
- CyclicBarrier: 循环栅栏
- Semaphore: 信号灯
5.1CountDownLatch(减少计数)
CountDownLatch类是Java中提供的一个同步工具类,它可以用于协调多个线程之间的执行。它具有以下特点:
- 倒计数功能:CountDownLatch内部维护一个计数器,该计数器可以被线程递减。在CountDownLatch对象被创建时,您可以指定计数器的初始值。每个线程在完成一定的操作后,可以使用
countDown()方法减少计数器的值。- 等待功能:线程可以通过调用
await()方法来等待计数器达到零。如果计数器的值非零,线程将被阻塞。一旦计数器的值为零,所有等待的线程将被唤醒,并继续执行。- 线程安全:CountDownLatch类是线程安全的,可以在多个线程之间共享和使用。它使用锁和同步机制来确保多线程访问的安全性。
- 一次性使用:一旦计数器的值达到零,CountDownLatch对象就不能再次使用。如果要进行多次倒计数操作,需要创建新的CountDownLatch对象。
CountDownLatch类常用于一些并发编程场景,例如某个线程需要等待多个其他线程执行完成后再继续执行,或者多个线程需要等待某个共享资源准备完毕后才能使用。它提供了一种简单而有效的方法来协调和控制线程之间的执行顺序和并发性。
基于CountDownLatch的特点,模拟如下场景:
一个班中还有7名同学。其中1名同学为班长(主线程),只有当6名同学(6个多线程)全部都走后,班长才能锁门离开。
不采用CountDownLatch测试:
public class CountDownLatchDemo {
public static void main(String[] args) {
for (int i = 1; i <= 6; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName() + "号同学离开了!");
},String.valueOf(i)).start();
}
System.out.println("班长锁门离开");
}
}可以看出主线程未等待其他线程直接结束。

采用CountDownLatch测试:
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 1; i <= 6; i++) {
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + "号同学离开了!");
} finally {
countDownLatch.countDown();
}
}, String.valueOf(i)).start();
}
countDownLatch.await();
System.out.println("班长锁门离开");
}
}
5.2CyclicBarrier(循环栅栏)
CyclicBarrier 类是 Java 中的一个同步工具类,用于控制多个线程的同步。它可以让一组线程在一个临界点处相互等待,直到所有线程都到达该点后才能继续执行。
CyclicBarrier 的构造函数接受一个整数作为参数,用于指定线程数量,以及一个可选的 Runnable 对象。当线程数量达到指定值时,所有线程将释放等待状态,并且可选择地执行指定的 Runnable。
主要的方法有:
CyclicBarrier(int parties):创建一个 CyclicBarrier 对象,指定要同步的线程数量。CyclicBarrier(int parties, Runnable barrierAction):创建一个 CyclicBarrier 对象,指定要同步的线程数量和当线程达到临界点时要执行的动作。await():在临界点等待,直到所有线程都到达该点。
CyclicBarrier 类的使用场景包括:多个线程需要等待彼此完成某个子任务,然后才能继续进行下一步操作;多个线程并行执行任务,并在某个点进行汇总计算等。
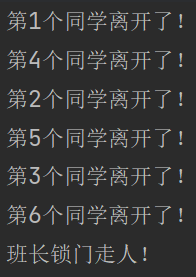
以CyclicBarrier类为例,模拟班级锁门案例
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierDemo {
private static final Integer NUMBER = 6;
public static void main(String[] args) {
// 创建CyclicBarrier对象,设置为6个线程,当6个线程都到达时,执行Runnable接口
CyclicBarrier cyclicBarrier = new CyclicBarrier(NUMBER, () -> {
System.out.println("班长锁门走人!");
});
for (int i = 1; i <= 6; i++) {
new Thread(() -> {
try {
System.out.println("第" + Thread.currentThread().getName() + "个同学离开了!");
// 等待
cyclicBarrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
}, String.valueOf(i)).start();
}
}
}
5.3Semaphore(信号灯)
Semaphore 类是一个同步工具类,用于控制对资源的访问。它可以管理对资源的许可数量,控制同时访问资源的线程数量。
Semaphore 维护一个许可的计数器,该计数器表示当前可用的许可数量。线程可以通过调用 acquire() 方法请求许可,如果许可数量大于0,则线程将获得许可,并将计数器减1;如果许可数量为0,则线程将被阻塞,直到有其他线程释放许可。线程使用完资源后,可以通过调用 release() 方法释放许可,将计数器加1。
Semaphore就是基于信号量机制来实现的。信号量是一种用于控制对资源的访问的同步机制。Semaphore 类提供了一种可用于控制线程并发访问的信号量封装。
在计算机科学中,信号量是一个整数变量,用于控制对公共资源的访问。它主要包含两个基本操作:P(等待)和V(发信号)。P(等待)操作会使信号量减1,如果信号量的值小于0,则线程将被阻塞。V(发信号)操作会使信号量加1,从而释放一个等待的线程。
Semaphore 类使用了类似的概念。它维护了一个等待许可的计数器,当请求许可时,计数器减1,如果计数器的值小于等于0,则线程会被阻塞。当释放许可时,计数器加1,从而唤醒等待的线程。
主要的方法有:
Semaphore(int permits):创建一个 Semaphore 对象,指定初始许可数量。acquire():请求一个许可,并获得许可,计数器减1。如果没有可用的许可,则线程将被阻塞。release():释放一个许可,将计数器加1。
Semaphore 类的使用场景包括:限制同时访问某个资源的线程数量,控制并发的读写操作,以及其他需要控制资源访问的场景。
以停车位为例,6辆车占用3个车位:
import java.util.Random;
import java.util.concurrent.Semaphore;
public class SemaphoreDemo {
private static final Integer NUMBER = 3;
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(NUMBER);
for (int i = 1; i <= 6; i++) {
new Thread(() -> {
try {
// 获取许可
semaphore.acquire();
System.out.println("第" + Thread.currentThread().getName() + "个汽车抢到了车位!");
// 汽车停留时间
Thread.sleep(new Random().nextInt(5));
System.out.println("第" + Thread.currentThread().getName() + "个汽车离开了车位!");
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
// 释放许可
semaphore.release();
}
}, String.valueOf(i)).start();
}
}
}
5.4总结
- CountDownLatch(倒计时门闩):
-CountDownLatch内部维护一个state变量,表示等待的计数器。初始值由用户指定,通常代表了需要等待的线程数量。
- 当一个线程调用countDown方法时,它会获取AQS的共享锁,并将state减少1。如果state变为0,表示所有等待的线程都已经完成,此时所有等待的线程都会被释放。
- 例如,如果初始计数器为3,那么需要调用3次countDown方法,每次调用都会将state减1,当state变为0时,等待的线程将被唤醒。 - CyclicBarrier(循环屏障):
-CyclicBarrier也使用AQS的共享模式,它内部维护一个state变量,表示已经到达的线程数量。
- 每个线程调用await方法时,会尝试获取AQS的共享锁,并将state递增。如果递增后的state等于指定的屏障点(barrier),则表示已经到达了屏障点,此时所有等待的线程都会被同时释放。
- 例如,如果指定的屏障点是3,那么需要3个线程调用await方法,每次调用都会递增state,当state等于3时,所有等待的线程将被释放。 - Semaphore(信号量):
-Semaphore内部维护一个state变量,表示信号量的可用许可数量。
- 当一个线程调用acquire方法时,它会尝试获取AQS的共享锁,并等待直到state大于0,然后将state减1,表示获取了一个许可。
- 当一个线程调用release方法时,也会获取AQS的共享锁,并将state递增,表示释放了一个许可,可以唤醒等待的线程。
- 信号量通常用于控制同时访问某一资源的线程数量。
6.阻塞队列
6.1 BlockingQueue 简介
Concurrent 包中,BlockingQueue 接口很好的解决了多线程中,如何高效安全 “传输”数据的问题。通过这些高效并且线程安全的队列类,为我们快速搭建 高质量的多线程程序带来极大的便利。
阻塞队列,顾名思义,首先它是一个队列, 通过一个共享的队列,可以使得数据由队列的一端输入,从另外一端输出;
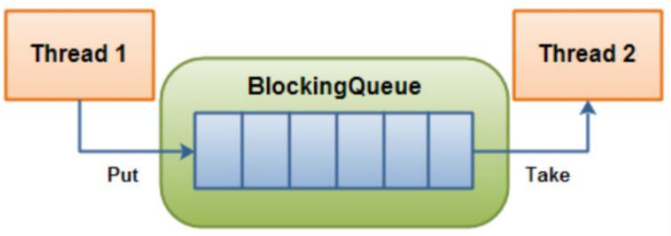
试图从空的队列中获取元素的线程将会被阻塞,直到其他线程往空的队列插入新的元素
试图向已满的队列中添加新元素的线程将会被阻塞,直到其他线程从队列中移除一个或多个元素。
6.2BlockingQueue接口详解
BlockingQueue是Java中的一个接口,它继承自Queue接口,用于实现多线程之间的安全数据传输。
BlockingQueue提供了一种阻塞操作的机制,当队列为空时,获取元素的操作会被阻塞,直到队列中有元素可用;当队列满时,插入元素的操作会被阻塞,直到队列中有空间可用。
BlockingQueue接口包含以下主要方法:
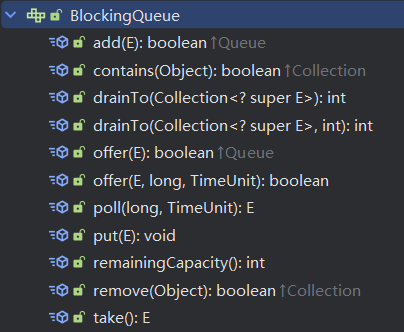
add(E element): 将元素插入队列,如果队列已满则抛出异常。contains(Object element): 检查队列是否包含指定的元素。drainTo(Collection<? super E> collection): 将队列中的所有元素移动到指定的集合中。drainTo(Collection<? super E> collection, int maxElements): 将队列中的最多maxElements个元素移动到指定的集合中。offer(E element): 将元素插入队列,如果队列已满则返回 false。offer(E element, long timeout, TimeUnit unit): 将元素插入队列,如果队列已满则等待指定的时间,如果在等待期间队列有空间可用,则插入元素并返回 true,否则返回 false。poll(long timeout, TimeUnit unit): 获取并移除队列的头部元素,如果队列为空则等待指定的时间,如果在等待期间队列有元素可取,则取出并返回该元素,否则返回 null。put(E element): 将元素插入队列,如果队列已满则阻塞当前线程,直到队列有空间可用。remainingCapacity(): 返回队列中剩余的可用空间大小。remove(Object element): 从队列中移除指定的元素,如果成功移除则返回 true。take(): 获取并移除队列的头部元素,如果队列为空则阻塞当前线程,直到队列有元素可取。
总结如下:
| 方法类型 | 抛出异常 | 特殊值 | 阻塞 | 超时 |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除 | remove(e) | poll() | take() | poll(time,unit) |
BlockingQueue的常用实现类包括:
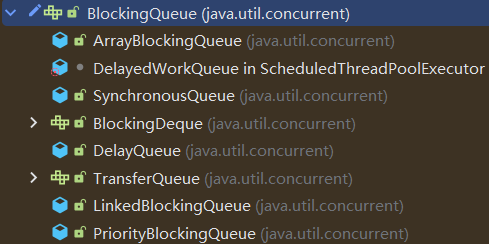
ArrayBlockingQueue: 基于数组实现的有界阻塞队列。LinkedBlockingQueue: 基于链表实现的可选有界阻塞队列。PriorityBlockingQueue: 基于优先级堆实现的无界阻塞队列。
测试:
- 队列满的情况:使用add添加时出现异常
public class BlockingQueueDemo {
public static void main(String[] args) {
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(3);
blockingQueue.add("a");
blockingQueue.add("b");
blockingQueue.add("c");
System.out.println(blockingQueue.size());
blockingQueue.add("d");
}
}
- 使用remove从队列中取出元素,当无元素而再从中取元素的时候出现异常
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class BlockingQueueDemo {
public static void main(String[] args) {
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(3);
System.out.println(blockingQueue.offer("a"));;
System.out.println(blockingQueue.offer("b"));;
System.out.println(blockingQueue.offer("c"));;
System.out.println(blockingQueue.size());
System.out.println(blockingQueue.remove());;
System.out.println(blockingQueue.remove());;
System.out.println(blockingQueue.remove());;
System.out.println(blockingQueue.remove());;
}
}
- 队列满的情况:使用offer添加时出现false
public class BlockingQueueDemo {
public static void main(String[] args) {
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(3);
System.out.println(blockingQueue.offer("a"));;
System.out.println(blockingQueue.offer("b"));;
System.out.println(blockingQueue.offer("c"));;
System.out.println(blockingQueue.size());
System.out.println(blockingQueue.offer("d"));;
}
}
- 使用poll从队列中取出元素,当无元素而再从中取元素的时候出现false
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class BlockingQueueDemo {
public static void main(String[] args) {
BlockingQueue<String> blockingQueue = new ArrayBlockingQueue<>(3);
System.out.println(blockingQueue.offer("a"));;
System.out.println(blockingQueue.offer("b"));;
System.out.println(blockingQueue.offer("c"));;
System.out.println(blockingQueue.size());
System.out.println(blockingQueue.poll());;
System.out.println(blockingQueue.poll());;
System.out.println(blockingQueue.poll());;
System.out.println(blockingQueue.poll());;
}
}
7.线程池
7.1线程池概述
线程池(Thread pool)的目的是通过重用线程来减少线程的创建和销毁的开销,并有效地利用系统资源。它可以提高程序的性能和响应性,并且可以控制并发的数量,防止系统资源被过度占用。
Java中的线程池是通过java.util.concurrent.Executors类提供的工厂方法来创建的。其中常见的线程池类型包括:
newFixedThreadPool:固定大小的线程池,创建一个固定数量的线程执行任务。newCachedThreadPool:可变大小的线程池,根据需要创建新线程,重用空闲线程,自动关闭空闲超过指定时间的线程。newSingleThreadExecutor:单个线程的线程池,创建一个单独的线程执行任务。newScheduledThreadPool:具有定时和周期性执行任务的线程池。
使用线程池,可以通过以下步骤来执行任务:
- 创建一个线程池对象,可以使用线程池工厂方法
Executors创建不同类型的线程池。- 创建一个实现
Runnable或Callable接口的任务对象,表示要执行的任务。- 将任务提交给线程池,线程池会根据具体类型的线程池选择适当的线程来执行任务。
- 线程池调度线程来执行任务,并处理线程的创建、销毁和线程之间的切换逻辑。
使用线程池可以提高程序的性能和可伸缩性,并且可以更好地控制线程的执行。它还可以避免手动管理线程的复杂性和风险。
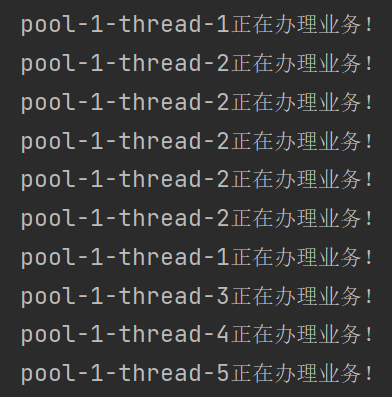
7.2newFixedThreadPool
固定大小的线程池,创建一个固定数量的线程执行任务。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newFixedThreadPool(5);
try {
for (int i = 1; i <= 10; i++) {
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "正在办理业务!");
});
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
7.3newSingleThreadExecutor
单个线程的线程池,创建一个单独的线程执行任务。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newSingleThreadExecutor();
try {
for (int i = 1; i <= 10; i++) {
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "正在办理业务!");
});
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
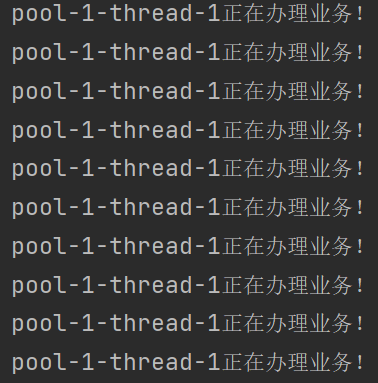
7.4newCachedThreadPool
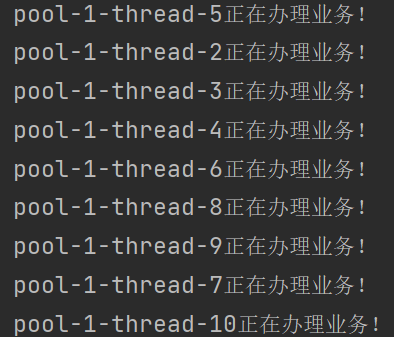
可变大小的线程池,根据需要创建新线程,重用空闲线程,自动关闭空闲超过指定时间的线程。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService threadPool = Executors.newCachedThreadPool();
try {
for (int i = 1; i <= 10; i++) {
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "正在办理业务!");
});
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
7.5ThreadPoolExecutor
7.5.1ThreadPoolExecutor概述
通过上述3个章节可以查看到newFixedThreadPool、newSingleThreadExecutor和newCacheThreadPool都是基于ThreadPoolExecutor来实现的。
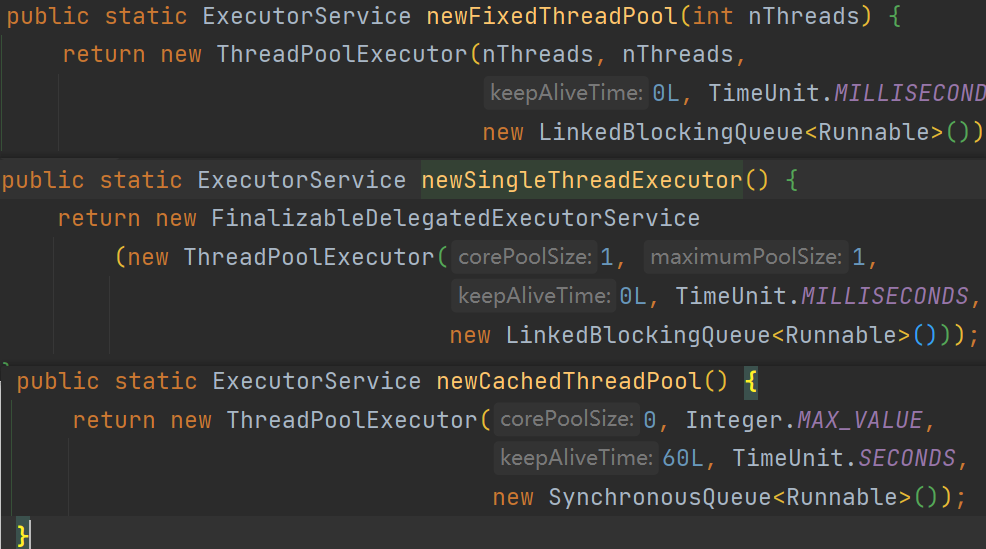
ThreadPoolExecutor 是Java 提供的一个强大的线程池实现类,在实际开发中经常被使用。而常见的线程池类型,如 FixedThreadPool、CachedThreadPool、SingleThreadExecutor 和 ScheduledThreadPool,基本上都是通过创建 ThreadPoolExecutor 的实例,并根据具体需求设置不同的参数来实现的。
ThreadPoolExecutor 提供了丰富的构造方法和配置选项,可以根据需求自定义线程池的大小、任务队列、线程工厂等参数。它是一个灵活可定制的线程池实现,可以满足不同场景下的需求。
由于 ThreadPoolExecutor 的灵活性,我们也可以自己扩展并实现自定义的线程池类型,根据具体需求做一些特定的优化和定制。4
7.5.2ThreadPoolExecutor方法的参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)JAVA
- int corePoolSize:核心线程数,线程会一直存在。
- int maximumPoolSize:最大线程数,控制资源。
- long keepAliveTime:存活时间,如果当前线程数量大于corePoolSize指定的线程数,并且已超过存活时间,就会释放除核心线程数之外的空闲线程。
- TimeUnit unit:时间单位
- BlockingQueue workQueue:阻塞队列。该队列是当核心线程没有空闲时,再来的请求放入队列中先保存任务。
- ThreadFactory threadFactory:线程的创建工厂。
- RejectedExecutionHandler handler:如果队列满了,按照拒绝策略拒绝执行任务。
7.5.3ThreadPoolExecutor方法执行流程
- 线程池创建,准备好 core 数量的核心线程,准备接受任务。新的任务进来,用 核心线程的空闲线程执行。
- 核心线程满了,就将再进来的任务放入阻塞队列中。空闲的核心线程就会自己去阻塞队列获取任务执行 。
- 阻塞队列满了,就直接开新线程执行,最大只能开到最大线程数指定的数量。
- 最大线程执行好了。Max-core 数量空闲的线程会在 keepAliveTime 指定的时间后自动销毁。最终保持到核心线程数的大小。
- 如果线程数开到了最大线程数的数量,还有新任务进来,就会使用 reject 指定的拒绝策略进行处理。
- 所有的线程创建都是由指定的 factory 创建的。
面试题:
一个线程池 core 7,max 20 ,queue:50,100 并发进来怎么分配的
7个被核心线程数执行,50个放入阻塞队列,开启新的线程执行,到达最大线程数时执行13个,大于最大线程数的30个被拒绝策略拒绝。
7.5.4拒绝策略
ThreadPoolExecutor 提供了以下几种常见的拒绝策略:
- AbortPolicy(默认策略):当线程池的任务队列已满并且线程池中的线程数达到最大线程数上限时,新提交的任务会抛出 RejectedExecutionException 异常。
- CallerRunsPolicy:当线程池的任务队列已满并且线程池中的线程数达到最大线程数上限时,新提交的任务会由提交任务的线程(Caller线程)直接执行。这种方式可以降低主线程的压力,但也可能会影响整体的性能。
- DiscardPolicy:当线程池的任务队列已满并且线程池中的线程数达到最大线程数上限时,新提交的任务会被丢弃,不会抛出任何异常。
- DiscardOldestPolicy:当线程池的任务队列已满并且线程池中的线程数达到最大线程数上限时,新提交的任务会尝试和任务队列中最早的任务竞争执行,如果竞争成功,则执行新任务,而最早的任务会被丢弃。
除了以上这些默认的拒绝策略外,开发者也可以自定义拒绝策略,只需要实现 RejectedExecutionHandler 接口,并实现其中的 rejectedExecution 方法,来定义自己的处理逻辑。
7.5.5自定义线程池
如下创建一个线程池:
核心线程数:20
最大线程数:200
线程存活时间:10
时间单位:SECONDS
阻塞队列:LinkedBlockingDeque
线程工厂:Executors.defaultThreadFactory()默认线程工厂
拒绝策略:AbortPolicy默认的拒绝策略
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 线程配置
*
* @date 2023/02/02
*/
@Configuration
public class ThreadConfig {
@Bean
public ThreadPoolExecutor threadPoolExecutor(ThreadPoolConfigProperties threadPool) {
return new ThreadPoolExecutor(
threadPool.getCoreSize(),
threadPool.getMaxSize(),
threadPool.getKeepAliveTime(),
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(100000),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
}
}/**
* 线程池配置属性
*
* @author Xu Huaiang
* @date 2023/02/02
*/
@Data
@Component
@ConfigurationProperties(prefix = "gulimall.thread")
public class ThreadPoolConfigProperties {
private Integer coreSize;
private Integer maxSize;
private Integer keepAliveTime;
}#线程池配置
gulimall:
thread:
core-size: 20
max-size: 200
keep-alive-time: 108.Fork/Join框架
8.1Fork/Join框架简介
Fork/Join 框架是一种并行编程模型,旨在简化分而治之(divide-and-conquer)算法的并行化。它是在Java 7中引入的,可用于编写高效且可伸缩的并行代码。
Fork/Join 框架基于两个主要的概念:fork(分叉)和 join(合并)。
- Fork:分支是指将一个大任务拆分成多个更小的子任务。这些子任务可以并行执行,以充分利用多核处理器的优势。
- Join:合并是指等待所有子任务完成,并将它们的结果聚合为一个最终结果。每个子任务在完成后,如果它们产生了结果,那么这些结 果会被合并到一个中间结果中,最终通过递归地合并这些中间结果来生成最终的结果。
Fork/Join 框架的使用需要以下几个关键组件:
- ForkJoinPool:一个线程池,用于执行任务。
- ForkJoinTask:表示可以被分割成多个子任务的任务抽象类。主要的子类有 RecursiveTask(有返回值的任务)和 RecursiveAction(无返回值的任务)。
- RecursiveTask:由需要返回结果的任务继承,任务可以递归地分割为子任务,每个子任务都可以在独立的线程中执行,并返回结果。
- RecursiveAction:由不需要返回结果的任务继承,任务可以递归地分割为子任务,每个子任务都可以在独立的线程中执行,无需返回结果。
使用 Fork/Join 框架可以有效地处理递归任务,并利用多核处理器的并行性能。它提供了一种简单而强大的机制来编写高性能的并行代码。
9.CompletableFuture
9.1Future接口
9.1.1Future接口概述
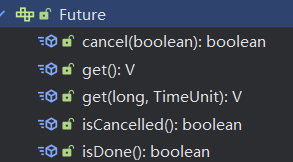
Future接口(实现类FutureTask)定义了操作异步任务一些方法,如获取异步任务的执行结果、取消异步任务的执行、判断任务是否被取消、判断任务执行是否完毕等。
Future接口定义了一组方法,可以用来操作异步计算的结果,其中包括:
- **isDone()**:判断异步计算是否已经完成。
- **cancel()**:尝试取消异步计算的执行。
- **get()**:获取异步计算的结果,如果计算尚未完成,则阻塞等待结果的返回。
- **get(timeout, unit)**:在给定的超时时间内,获取异步计算的结果,如果计算尚未完成,则阻塞等待结果的返回。
使用Future接口可以在提交任务后立即返回一个Future对象,然后可以根据需要来获取计算的结果。这样可以充分利用CPU资源,避免线程的阻塞等待。
9.3.1FutureTask类介绍
Thread类的构造方法没有直接接受Callable接口作为参数的构造方法。为了使用Callable接口,可以结合使用Callable和FutureTask来实现多线程。
- Runnable接口有实现类FutureTask
- FutureTask类的构造函数可以由Callable接口作为参数
FutureTask是Java中的一个实现了Future接口和Runnable接口的类,它可以实现多线程、异步任务以及返回结果。

FutureTask类的重要方法
- 构造方法:
- FutureTask(Callable
callable):使用给定的Callable创建一个FutureTask对象。 - FutureTask(Runnable runnable, V result):使用给定的Runnable和结果值创建一个FutureTask对象。
- 获取结果:
- V get():阻塞当前线程,直到任务完成并返回计算结果。
- V get(long timeout, TimeUnit unit):阻塞当前线程,最多等待指定的时间,如果任务完成则返回计算结果。
- 判断任务状态:
- boolean isDone():判断任务是否完成。
- boolean isCancelled():判断任务是否被取消。
- 取消任务:
- boolean cancel(boolean mayInterruptIfRunning):取消任务的执行。参数mayInterruptIfRunning表示是否中断正在执行的任务。
FutureTask类的特点
- 异步计算:FutureTask类允许您执行异步计算,即任务可以在后台线程中执行,而不会阻塞主线程。这使得您可以在进行其他操作的同时等待计算的结果。
- 可取消任务:FutureTask类允许您取消正在执行的任务。您可以调用cancel()方法来请求取消任务,并传递一个布尔值来指定是否应中断执行任务的线程。这对于在等待计算结果时需要提前终止任务的情况非常有用。
- 获取计算结果:FutureTask类提供了获取计算结果的方法。您可以使用get()方法来阻塞当前线程,直到计算完成并返回结果。如果计算尚未完成,调用get()将阻塞直到结果可用。
- 支持回调函数:FutureTask类允许您在计算完成时执行回调函数。您可以使用done()方法注册回调函数,当计算完成时会自动调用该函数。这对于在计算结果可用时执行其他操作或处理结果非常有用。
- 线程安全:FutureTask类是线程安全的,可以在多个线程之间共享和使用。它使用锁和同步机制来确保多线程访问的安全性。
9.3.2Future接口的缺点
Future接口的主要缺点包括:
- 阻塞:当调用Future的get()方法时,如果异步任务还未完成,get()方法会一直阻塞,直到任务完成并返回结果。
- 轮询:如果不想使用阻塞的get()方法,可以使用
isDone()方法和get()方法的重载版本来判断任务是否完成。但是这种方式需要手动进行轮询,不断地检查任务的完成状态,这样会消耗CPU资源,并且代码也会变得复杂。- 不支持异常处理:Future接口的get()方法会抛出ExecutionException异常,该异常会包装任务执行过程中产生的异常。但是在任务执行过程中,如果抛出异常,我们无法在Future接口中进行异常处理,需要通过try-catch语句对get()方法的调用进行处理。
- 缺乏组合性:Future接口只能表示一个单独的异步任务,如果需要组合多个异步任务的结果,就需要手动进行编写组合逻辑。这样会导致代码冗余和可读性下降。
综上所述,Future接口的主要缺点是阻塞、轮询、不支持异常处理和缺乏组合性。为了解决这些问题,Java 8引入了CompletableFuture类来提供更强大且灵活的异步编程方式。
9.2Callable接口
9.2.1Callable接口概述
Callable接口是Java中的一个泛型接口,它的目的是代表一个可以返回结果并能抛出异常的任务。Callable接口定义了一个名为call()的方法,该方法在任务执行时被调用,并返回一个结果对象。
9.2.2Callable和Runnable接口的区别
Callable接口和Runnable接口是Java中用于创建多线程任务的两个接口,它们有以下主要区别:
- 返回值:
Runnable接口的run()方法没有返回值,而Callable接口的call()方法可以返回一个结果。通过Callable执行的任务可以返回一个结果对象,而Runnable执行的任务没有返回值。- 异常处理:
Runnable接口的run()方法不能抛出受检查的异常,只能抛出未受检查的异常。而Callable接口的call()方法可以抛出受检查的异常。- Future对象:
Runnable任务没有返回值,也无法获取执行结果。而Callable任务可以通过Future对象来获取执行结果。Future表示异步计算的结果,它提供了获取任务执行状态、取消任务和获取任务执行结果的方法。
9.2.3Callable+FutureTask实现多线程
Callable + FutureTask是实现多线程、异步任务并获得返回结果的机制。
CallableTest类实现Callable接口
class CallableTest implements Callable {
@Override
public String call() throws Exception {
System.out.println(Thread.currentThread().getName() + "开始执行!");
return "Callable返回值";
}
}- main方法
public class RunnableCallable {
public static void main(String[] args) {
FutureTask futureTask = new FutureTask<>(new CallableTest());
Thread thread01 = new Thread(futureTask, "线程01");
thread01.start();
Object result = null;
try {
thread01.join();
result = futureTask.get();
} catch (Exception e) {
throw new RuntimeException(e);
}
System.out.println("在main方法中获取到Callable的返回值:" + result);
}
}
9.3CompletableFuture类
9.3.1CompletableFuture类概述
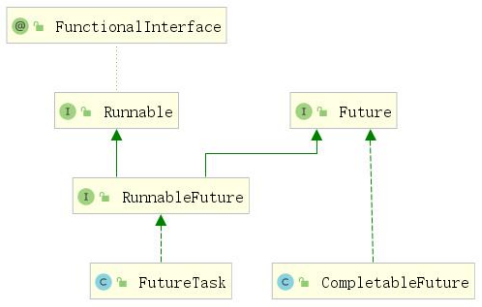
CompletableFuture类是Java 8中引入的一种异步编程模型,专门用于处理异步计算任务和任务之间的依赖关系。它被设计为Future的扩展,提供了更加灵活和强大的功能。
CompletableFuture出现的主要原因是为了解决传统Future在处理异步编程时存在的一些限制和不足。传统的Future模型只提供了基本的异步计算机制,例如提交任务、获取结果和取消任务等,但是它在处理任务之间的依赖关系、异常处理和结果组合等方面较为繁琐和有限。
CompletableFuture提供了一系列的方法和组合操作,使得我们能够更加方便地处理异步计算任务和任务之间的关系。它支持链式调用,可以通过一系列的操作来组合多个CompletableFuture对象,实现任务的串行、并行或者任意组合。同时,CompletableFuture还提供了异常处理的机制,可以更加灵活地处理任务执行过程中的异常情况。
CompletableFuture 和 FutureTask 同属于 Future 接口的实现类,都可以获取线程的执行结果。
9.3.2CompletableFuture原理
由于CompletableFuture是Future接口和CompletionStage接口的实现类。
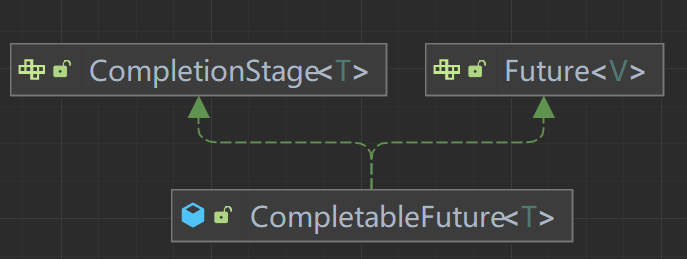
Future接口代表一个异步计算的结果。它提供了一种在异步计算完成后获取结果的方式。
CompletionStage接口是一个用于处理异步计算过程的接口。它是Future接口的扩展,并且提供了更加灵活和强大的功能。CompletionStage接口定义了一系列方法,用于对异步计算的结果进行处理、组合和转换。它提供了一种方便的方式来处理异步任务的完成事件,并且可以将多个阶段按照一定的顺序串联起来执行。而
CompletableFuture是CompletionStage接口的一个实现类,它在Future的基础上增加了很多便利的方法和功能,使得异步编程更加灵活和强大。
下面是CompletableFuture的一些原理:
- 链式调用:
CompletableFuture的方法通常返回一个新的CompletableFuture对象,可以通过链式调用来依次处理任务的结果。这种方式简化了代码的编写,并且允许我们以更直观的方式组合多个异步操作。- 异步执行:
CompletableFuture通过内部线程池来执行任务。当我们调用supplyAsync()、runAsync()或者thenXXXAsync()方法时,任务会通过内部线程池中的线程来异步执行。这样可以避免阻塞主线程,提高任务的并发性能。- 异步任务的依赖关系:
CompletableFuture通过thenApply()、thenAccept()、thenCombine()等方法来定义异步任务之间的依赖关系。这些方法接受一个函数或者操作,用来处理上一个任务的结果,并返回一个新的CompletableFuture对象,以便链式调用。- 异常处理:
CompletableFuture提供了exceptionally()、handle()等方法来处理异步任务中可能发生的异常。这些方法可以捕获异常并进行相应的处理,例如返回默认值或者执行补偿操作,以保证整个异步链的顺利完成。- 等待任务完成和获取结果:与
Future接口不同,CompletableFuture提供了一种非阻塞的方式来等待任务的完成并获取结果。我们可以使用join()或者getNow()方法来等待任务完成并返回结果,从而避免了任务完成前的阻塞。
总体来说,CompletableFuture通过链式调用、异步执行、依赖关系、异常处理以及非阻塞的任务等待方式,提供了一种灵活且强大的异步编程工具,使得处理异步任务变得更加简单和高效。
9.3.3创建异步对象
9.3.3.1创建异步对象的方式
CompletableFuture 提供了四个静态方法来创建一个异步对象。

runAsync都是没有返回结果的,supplyAsync都是可以获取返回结果的runAsync(Runnable runnable):接受一个Runnable类型的参数,表示一个没有输入参数和返回结果的操作。在异步执行期间,将调用该runnable操作。runAsync(Runnable runnable, Executor executor):除了接受一个Runnable参数外,还接受一个Executor参数,用于指定在哪个执行器上执行异步操作。supplyAsync(Supplier<U> supplier):接受一个Supplier类型的参数,表示一个没有输入参数但有返回结果的函数。在异步执行期间,将调用该supplier函数并获取其返回值。supplyAsync(Supplier<U> supplier, Executor executor):除了接受一个Supplier参数外,还接受一个Executor参数,用于指定在哪个执行器上执行异步操作。
9.3.3.2runAsync
runAsync是没有返回值的异步对象。
import java.util.concurrent.*;
// 线程池
class ThreadPoolExecutorProvider {
public static ThreadPoolExecutor getThreadPool() {
return new ThreadPoolExecutor(10,
20,
10,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(100),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
}
}
public class runAsyncDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {
System.out.println("当前线程" + Thread.currentThread().getName() + "。基于runAsync创建异步对象");
},threadPool);
try {
completableFuture.get();
} catch (Exception e) {
throw new RuntimeException(e);
}finally {
threadPool.shutdown();
}
}
}
9.3.3.3supplyAsync
supplyAsync是有返回值的异步对象。
public class supplyAsyncDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程" + Thread.currentThread().getName() + "。基于supplyAsync创建异步对象");
return "我是supplyAsync对象的返回值";
}, threadPool);
try {
String result = completableFuture.get();
System.out.println("获取到的返回结果:" + result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown() ;
}
}
}
9.3.4对结果进行处理
9.3.4.1对结果进行处理的方式
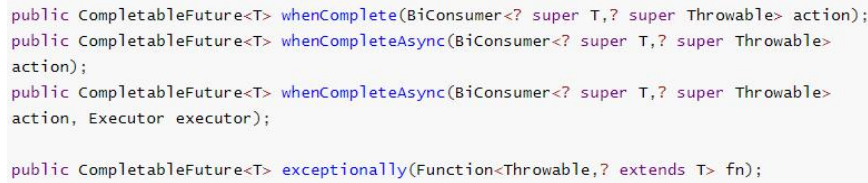
whenComplete: 可以处理正常和异常的返回结果,无返回值。这个函数接受两个参数:计算结果的值(如果成功完成),或者是一个
Throwable类型的异常(如果计算抛出了异常)
whenCompleteAsync:与whenComplete相比,whenCompleteAsync是把任务交给线程池来进行执行。
exceptionally:处理异常情况,并返回一个值作为替代结果。这个函数接受一个
Throwable类型的参数,即计算过程中抛出的异常
handle:可以处理正常和异常的返回结果,有返回值。这个函数接受两个参数:计算结果的值(如果成功完成),或者是一个
Throwable类型的异常(如果计算抛出了异常)
handleAsync:与handle相比,handleAsync是把任务交给线程池来进行执行。
thenApply:可以处理返回结果,有返回值。这个函数接受一个参数,即原始
CompletableFuture的计算结果,返回一个转换后的结果。
thenApplyAsync:与thenApply相比,thenApplyAsync是把任务交给线程池来进行执行。
thenAccept:可以处理返回结果,无返回值。这个函数接受一个参数,表示计算结果的值,但没有返回值。
thenAcceptAsync:与thenAccept相比,thenAcceptAsync是把任务交给线程池来进行执行。
thenRun:不获取返回值,只要上面的任务执行完成,就开始执行thenRun。这个函数的参数是一个
Runnable类型的函数,它不接受任何参数。也就是说,你可以传递一个没有参数的函数或者使用Lambda表达式来定义一个没有参数的操作。
thenRunAsync:与thenRun相比,thenRunAsync是把任务交给线程池来进行执行。


9.3.4.2whenComplete&whenCompleteAsync
whenComplete&whenCompleteAsync: 可以处理正常和异常的返回结果,无返回值。
这个函数接受两个参数:计算结果的值(如果成功完成),或者是一个Throwable类型的异常(如果计算抛出了异常)
- 正常情况
public class WhenCompleteDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
try {
CompletableFuture<Integer> result = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
return number;
}, threadPool).whenCompleteAsync((v, e) -> {
if (Optional.ofNullable(v).isPresent()) {
System.out.println("获取到的返回结果number:" + v);
}
if (Optional.ofNullable(e).isPresent()) {
System.out.println(e.getMessage());
}
}, threadPool);
System.out.println("最终获取到的计算结果为:" + result.join());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
- 出现异常
public class WhenCompleteDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
try {
CompletableFuture<Integer> result = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
number = number / 0;
return number;
}, threadPool).whenCompleteAsync((v, e) -> {
if (Optional.ofNullable(v).isPresent()) {
System.out.println("获取到的返回结果number:" + v);
}
if (Optional.ofNullable(e).isPresent()) {
System.out.println(e.getMessage());
}
}, threadPool);
System.out.println("最终获取到的计算结果为:" + result.join());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.4.3exceptionally
exceptionally:处理异常情况,并返回一个值作为替代结果。
这个函数接受一个Throwable类型的参数,即计算过程中抛出的异常
public class ExceptionallyDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
try {
CompletableFuture<Integer> result = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
number = number / 0;
return number;
}, threadPool).whenCompleteAsync((v, e) -> {
if (Optional.ofNullable(v).isPresent()) {
System.out.println("获取到的返回结果number:" + v);
}
if (Optional.ofNullable(e).isPresent()) {
System.out.println(e.getMessage());
}
}, threadPool).exceptionally((e) -> {
System.out.println("exceptionally中获取到异常信息:" + e.getMessage());
return 0;
});
System.out.println("最终获取到的计算结果为:" + result.join());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.4.4handle&handleAsync
handle&handleAsync:可以处理正常和异常的返回结果,有返回值。
这个函数接受两个参数:计算结果的值(如果成功完成),或者是一个Throwable类型的异常(如果计算抛出了异常)
public class HandleDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
try {
CompletableFuture<Integer> result = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
return number;
}, threadPool).handleAsync((v, e) -> {
System.out.println("在handle中获取到supplyAsync中的返回值为:" + v);
int number = v + 6;
return number;
}, threadPool);
System.out.println("最终获取到的计算结果为:" + result.join());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.4.5thenApply&thenApplyAsync
thenApply&thenApplyAsync可以处理返回结果,有返回值。
这个函数接受一个参数,即原始CompletableFuture的计算结果,返回一个转换后的结果。
public class thenApplyDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
try {
CompletableFuture<Integer> result = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
return number;
}, threadPool).thenApplyAsync((v) -> {
System.out.println("在thenApplyAsync中处理结果");
return v + 6;
});
System.out.println("最终获取到的计算结果为:" + result.join());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.4.6thenAccept&thenAcceptAsync
thenAccept&thenAcceptAsync :可以处理返回结果,无返回值。
这个函数接受一个参数,表示计算结果的值,但没有返回值。
public class ThenAcceptDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
try {
CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
return number;
}, threadPool).thenAcceptAsync((v) -> {
System.out.println("在thenApplyAsync中处理结果,没有返回值");
System.out.println("在thenAcceptAsync获取到最终结果:" + (v + 6));
});
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
threadPool.shutdown();
}
}
}
9.3.4.7thenRun&thenRunAsync
thenRun&thenRunAsync :不获取返回值,只要上面的任务执行完成,就开始执行 thenRun。
这个函数的参数是一个Runnable类型的函数,它不接受任何参数。也就是说,你可以传递一个没有参数的函数或者使用Lambda表达式来定义一个没有参数的操作。
public class ThenRunDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
try {
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
return number;
}, threadPool).thenRunAsync(() -> {
System.out.println("在thenRunAsync中不能获取到结果,没有返回值。");
});
System.out.println(future.join());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.5任务组合
9.3.5.1两两任务组合—都完成
9.3.5.1.1两两任务组合都完成的方式

thenCombine:组合两个 future,获取两个 future 的执行结果,并返回当前任务的返回值。thenAcceptBoth:组合两个 future,获取两个 future 任务的执行结果,然后处理任务,没有返回值。runAfterBoth:组合两个 future,不需要获取 future 的结果,只需两个 future 处理完任务后, 处理该任务。
9.3.5.1.2thenCombine&thenCombineAsync
thenCombine&thenCombineAsync:组合两个 future,获取两个 future 的执行结果,并返回当前任务的返回值。
public class ThenCombineDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
CompletableFuture<Integer> thread01 = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
CompletableFuture<Integer> thread02 = CompletableFuture.supplyAsync(() -> {
int number = 3 + 4;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
CompletableFuture<Integer> result = thread01.thenCombineAsync(thread02, (t1, t2) -> {
return t1 + t2;
}, threadPool);
try {
Integer addResult = result.join();
long end = System.currentTimeMillis();
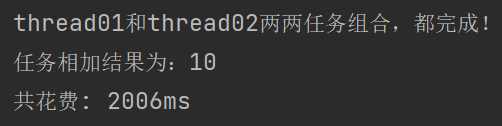
System.out.println("thread01和thread02两两任务组合,都完成!" + "\n" + "任务相加结果为:" + addResult);
System.out.println("共花费: " + (end - start) + "ms");
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.5.1.2thenAcceptBoth&thenAcceptBothAsync
thenAcceptBoth&thenAcceptBothAsync:组合两个 future,获取两个 future 任务的执行结果,然后处理任务,没有返回值。
public class ThenAcceptBothDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
CompletableFuture<Integer> thread01 = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
CompletableFuture<Integer> thread02 = CompletableFuture.supplyAsync(() -> {
int number = 3 + 4;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
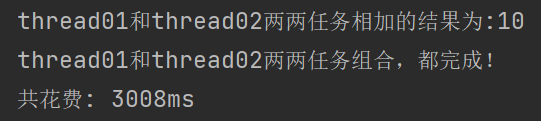
thread01.thenAcceptBothAsync(thread02, (t1, t2) -> {
int result = t1 + t2;
System.out.println("thread01和thread02两两任务相加的结果为:" + result);
}, threadPool);
try {
Thread.sleep(3000);
long end = System.currentTimeMillis();
System.out.println("thread01和thread02两两任务组合,都完成!");
System.out.println("共花费: " + (end - start) + "ms");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
threadPool.shutdown();
}
}
}
9.3.5.1.3runAfterBoth&runAfterBothAsync
runAfterBoth&runAfterBothAsync:组合两个 future,不需要获取 future 的结果,只需两个 future 处理完任务后, 处理该任务。
public class RunAfterBothDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
CompletableFuture<Integer> thread01 = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
CompletableFuture<Integer> thread02 = CompletableFuture.supplyAsync(() -> {
int number = 3 + 4;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
thread01.runAfterBothAsync(thread02, () -> {
System.out.println("thread01和thread02两两任务执行后执行runAfterBothAsync");
}, threadPool);
try {
Thread.sleep(3000);
long end = System.currentTimeMillis();
System.out.println("thread01和thread02两两任务组合,都完成!");
System.out.println("共花费: " + (end - start) + "ms");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}finally {
threadPool.shutdown();
}
}
}
9.3.5.2两两任务组合—一个完成
9.3.5.1.1两两任务组合一个完成的方式
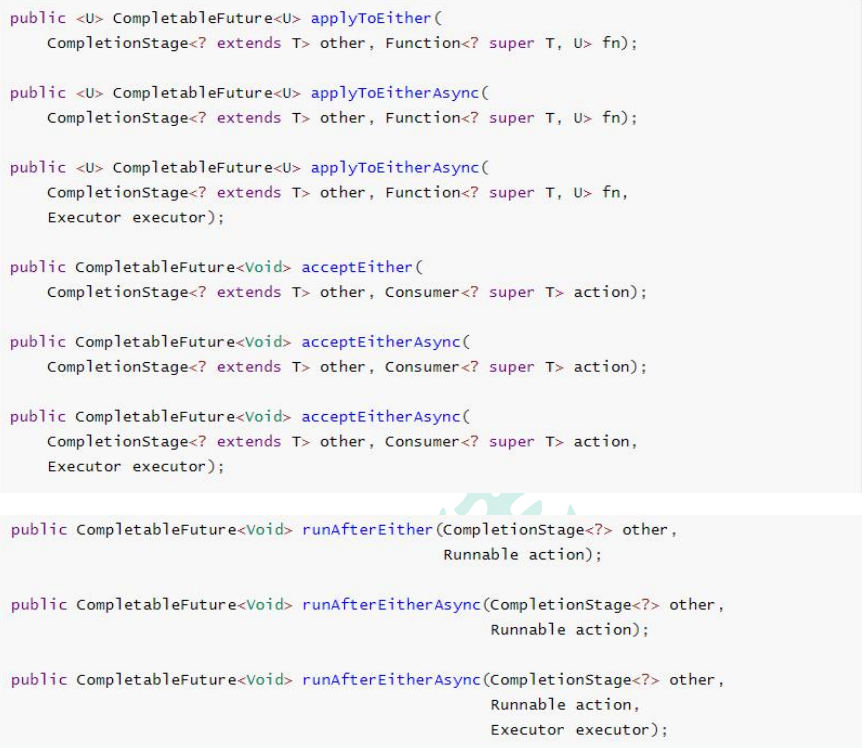
runAfterEither和acceptEither以及applyToEither都是当前阶段或other阶段中的一个已经完成(正常完成或异常完成),则使用完成的结果调用函数,将函数的返回值作为新的阶段的结果。如果两个阶段都未完成,那么新的阶段将等待其中的一个阶段完成后再次运行。applyToEither:获取到上一次的执行结果,并且有返回值acceptEither:获取到上一次的执行结果,但是没有返回值runAfterEither:不获取到上一次的执行结果,并且没有返回值
9.3.5.2.2applyToEither&applyToEitherAsync
applyToEither:获取到上一次的执行结果,并且有返回值
public class ApplyToEitherDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
CompletableFuture<Integer> thread01 = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
CompletableFuture<Integer> thread02 = CompletableFuture.supplyAsync(() -> {
int number = 3 + 4;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
CompletableFuture<Integer> result = thread01.applyToEitherAsync(thread02, (resultThread) -> {
return resultThread;
}, threadPool);
try {
Thread.sleep(1000);
long end = System.currentTimeMillis();
Integer number = result.join();
System.out.println("两两组合返回首先完成的异步任务结果:" + number);
System.out.println("共花费:" + (end - start) + "ms");
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.5.2.3acceptEither&acceptEitherAsync
acceptEither&acceptEitherAsync:获取到上一次的执行结果,但是没有返回值
public class AcceptEitherDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
CompletableFuture<Integer> thread01 = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
CompletableFuture<Integer> thread02 = CompletableFuture.supplyAsync(() -> {
int number = 3 + 4;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
thread01.acceptEitherAsync(thread02, (resultThread) -> {
System.out.println("acceptEitherAsync无返回值");
System.out.println("首先完成的异步任务的算结果为:" + resultThread);
}, threadPool);
try {
Thread.sleep(1000);
long end = System.currentTimeMillis();
System.out.println("共花费:" + (end - start) + "ms");
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.5.2.4runAfterEither&runAfterEitherAsync
runAfterEither:不获取到上一次的执行结果,并且没有返回值
public class RunAfterEitherDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
CompletableFuture<Integer> thread01 = CompletableFuture.supplyAsync(() -> {
int number = 1 + 2;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
CompletableFuture<Integer> thread02 = CompletableFuture.supplyAsync(() -> {
int number = 3 + 4;
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return number;
}, threadPool);
thread01.runAfterEitherAsync(thread02, () -> {
System.out.println("runAfterEitherAsync不会获取结果,无返回值");
}, threadPool);
try {
Thread.sleep(1000);
long end = System.currentTimeMillis();
System.out.println("共花费:" + (end - start) + "ms");
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.5.2多任务组合
9.3.5.2.1多任务组合的方式

- allOf:该方法接收一个或多个CompletableFuture对象,并返回一个CompletableFuture,当所有的CompletableFuture都完成时,这个CompletableFuture也会完成。它可以用于等待多个任务全部完成。
- anyOf:该方法接收一个或多个CompletableFuture对象,并返回一个CompletableFuture,当任一CompletableFuture完成时,这个CompletableFuture也会完成。它可以用于等待多个任务中的任意一个完成。
9.3.5.2.2allOf
allOf:该方法接收一个或多个CompletableFuture对象,并返回一个CompletableFuture,当所有的CompletableFuture都完成时,这个CompletableFuture也会完成。它可以用于等待多个任务全部完成。
public class AllOfDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
CompletableFuture<Integer> thread01 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
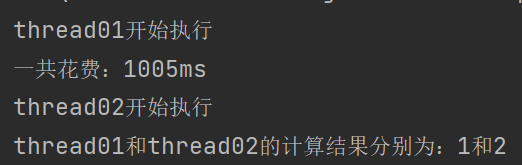
System.out.println("thread01开始执行");
return 1;
}, threadPool);
CompletableFuture<Integer> thread02 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("thread02开始执行");
return 2;
}, threadPool);
try {
// 等待所有的线程执行完毕
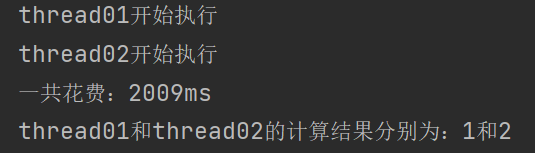
CompletableFuture.allOf(thread01, thread02).get();
long end = System.currentTimeMillis();
System.out.println("一共花费:" + (end - start) + "ms");
Integer thread01Result = thread01.join();
Integer thread02Result = thread02.join();
System.out.println("thread01和thread02的计算结果分别为:" + thread01Result + "和" + thread02Result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.5.2.2anyOf
anyOf:该方法接收一个或多个CompletableFuture对象,并返回一个CompletableFuture,当任一CompletableFuture完成时,这个CompletableFuture也会完成。它可以用于等待多个任务中的任意一个完成。
public class AllOfDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
CompletableFuture<Integer> thread01 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("thread01开始执行");
return 1;
}, threadPool);
CompletableFuture<Integer> thread02 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("thread02开始执行");
return 2;
}, threadPool);
try {
// 等待所有的线程执行完毕
CompletableFuture.anyOf(thread01, thread02).get();
long end = System.currentTimeMillis();
System.out.println("一共花费:" + (end - start) + "ms");
Integer thread01Result = thread01.join();
Integer thread02Result = thread02.join();
System.out.println("thread01和thread02的计算结果分别为:" + thread01Result + "和" + thread02Result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.6电商项目实战
/**
* 根据skuID获取到sku的详细信息
*
* @param skuId sku id
* @return {@link SkuItemVO}
*/
@Override
public SkuItemVO getSkuItemInfo(Long skuId) throws ExecutionException, InterruptedException {
SkuItemVO skuItemVO = new SkuItemVO();
CompletableFuture<SkuInfoEntity> infoFuture = CompletableFuture.supplyAsync(() -> {
// 1.获取到sku的基本信息 pms_sku_info
SkuInfoEntity skuInfo = getById(skuId);
skuItemVO.setSkuInfoEntity(skuInfo);
return skuInfo;
}, threadPoolExecutor);
// 2.以下三个任务都依赖于infoFuture的执行结果
// 3.获取spu的介绍
CompletableFuture<Void> descFuture = infoFuture.thenAcceptAsync((result) -> {
SpuInfoDescEntity spuInfoDescEntity = spuInfoDescService.getById(result.getSpuId());
skuItemVO.setDesp(spuInfoDescEntity);
}, threadPoolExecutor);
// 4.获取spu的基本属性信息
CompletableFuture<Void> baseAttrFuture = infoFuture.thenAcceptAsync((result) -> {
List<SpuItemAttrGroupVO> spuItemAttrGroupVOS = attrGroupService
.getAttrGroupWithAttrsBySpuId(result.getSpuId());
skuItemVO.setGroupVos(spuItemAttrGroupVOS);
}, threadPoolExecutor);
// 5.获取到spu的销售属性组合
CompletableFuture<Void> saleAttrFuture = infoFuture.thenAcceptAsync((result) -> {
List<SkuItemSaleAttrVO> saleAttrVOS =
skuSaleAttrValueService.getSaleAttrBySpuId(result.getSpuId());
skuItemVO.setSaleAttr(saleAttrVOS);
}, threadPoolExecutor);
// 6.获取到sku的图片信息 pms_sku_images
CompletableFuture<Void> imageFuture = CompletableFuture.runAsync(() -> {
List<SkuImagesEntity> skuImageInfo = skuImagesService.getSkuImageInfo(skuId);
skuItemVO.setImages(skuImageInfo);
});
// 等待所有任务完成
CompletableFuture
.allOf(descFuture,baseAttrFuture,saleAttrFuture,imageFuture)
.get();
return skuItemVO;
}9.3.5获取结果
9.3.5.1获取结果的方式
get():此方法会阻塞当前线程,直到CompletableFuture的结果可用并返回结果值。如果CompletableFuture还没有完成,该方法将一直阻塞。get(long timeout, TimeUnit unit): 获取异步操作的结果,但在指定的超时时间内。如果在超时时间内结果未可用,该方法会抛出TimeOutException。你可以指定超时时间和时间单位。join():与get()方法类似,join()方法也会阻塞当前线程,直到CompletableFuture的结果可用并返回结果值。getNow(T value):此方法会立即返回CompletableFuture的结果值,如果CompletableFuture尚未完成,则返回指定的默认值value。complete(T value):此方法用于手动完成CompletableFuture,并将结果设置为指定的值。手动完成异步操作后,任何等待该异步操作的阻塞方法(如get()或join())都会立即返回,并获取到对应的值。
get()和join()的区别
get()方法:get()方法是一个受检异常方法,所以在调用时需要处理InterruptedException和ExecutionException。但join()方法不会抛出任何受检异常,也不会中断当前线程。
9.3.5.2get()
get()方法直接获取返回值,如果CompletableFuture还没有完成,该方法将一直阻塞。
public class supplyAsyncDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
// 创建异步对象
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程" + Thread.currentThread().getName() + "。基于supplyAsync创建异步对象");
try {
// 模拟耗时操作
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "我是supplyAsync对象的返回值";
}, threadPool);
try {
// 获取返回值
String result = completableFuture.get();
long end = System.currentTimeMillis();
System.out.println("一共花费" + (end - start) + "ms");
System.out.println("获取到的返回结果:" + result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
get(long timeout, TimeUnit unit)设置超时时间,如果在超时时间内未获取到返回结果,则会报TimeOutException。
public class supplyAsyncDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
// 创建异步对象
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程" + Thread.currentThread().getName() + "。基于supplyAsync创建异步对象");
try {
// 模拟耗时操作
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "我是supplyAsync对象的返回值";
}, threadPool);
try {
// 获取返回值
String result = completableFuture.get(2000, TimeUnit.MICROSECONDS);
long end = System.currentTimeMillis();
System.out.println("一共花费" + (end - start) + "ms");
System.out.println("获取到的返回结果:" + result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.5.3join()
join():与get()方法类似,join()方法也会阻塞当前线程,直到CompletableFuture的结果可用并返回结果值。
public class supplyAsyncDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
// 创建异步对象
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程" + Thread.currentThread().getName() + "。基于supplyAsync创建异步对象");
try {
// 模拟耗时操作
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "我是supplyAsync对象的返回值";
}, threadPool);
try {
// 获取返回值
String result = completableFuture.join();
long end = System.currentTimeMillis();
System.out.println("一共花费" + (end - start) + "ms");
System.out.println("获取到的返回结果:" + result);
} finally {
threadPool.shutdown();
}
}
}
9.3.5.4getNow()
getNow(T value):此方法会立即返回CompletableFuture的结果值,如果CompletableFuture尚未完成,则返回指定的默认值value。
public class supplyAsyncDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
// 创建异步对象
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程" + Thread.currentThread().getName() + "。基于supplyAsync创建异步对象");
try {
// 模拟耗时操作
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "我是supplyAsync对象的返回值";
}, threadPool);
try {
// 获取返回值
String result = completableFuture.getNow("默认值");
long end = System.currentTimeMillis();
System.out.println("一共花费" + (end - start) + "ms");
System.out.println("获取到的返回结果:" + result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.5.5complete()
complete(T value):此方法用于手动完成CompletableFuture,并将结果设置为指定的值。手动完成异步操作后,任何等待该异步操作的阻塞方法(如get()或join())都会立即返回,并获取到对应的值。
public class supplyAsyncDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
// 创建异步对象
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程" + Thread.currentThread().getName() + "。基于supplyAsync创建异步对象");
try {
// 模拟耗时操作
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "我是supplyAsync对象的返回值";
}, threadPool);
try {
// 获取返回值
completableFuture.complete("默认值");
String result = completableFuture.join();
long end = System.currentTimeMillis();
System.out.println("一共花费" + (end - start) + "ms");
System.out.println("获取到的返回结果:" + result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
public class supplyAsyncDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
long start = System.currentTimeMillis();
// 创建异步对象
CompletableFuture<String> completableFuture = CompletableFuture.supplyAsync(() -> {
System.out.println("当前线程" + Thread.currentThread().getName() + "。基于supplyAsync创建异步对象");
try {
// 模拟耗时操作
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
return "我是supplyAsync对象的返回值";
}, threadPool);
try {
Thread.sleep(2000);
// 获取返回值
completableFuture.complete("默认值");
String result = completableFuture.get();
long end = System.currentTimeMillis();
System.out.println("一共花费" + (end - start) + "ms");
System.out.println("获取到的返回结果:" + result);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
9.3.6异步任务执行时的线程选择
从10.3.4章中可以看出,CompletableFuture中提供的方法有两种,一种是使用默认的线程池,另一种是可以使用自定义的线程池。可以查看线程的使用情况:
- 使用默认的线程池
public class AsyncTaskThreadDemo {
public static void main(String[] args) {
CompletableFuture.runAsync(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + ":A计划");
}).thenRun(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + ":B计划");
}).thenRun(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + ":C计划");
});
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}查看线程如下:可以看出默认使用的是ForkJoinPool线程池当中的同一线程。
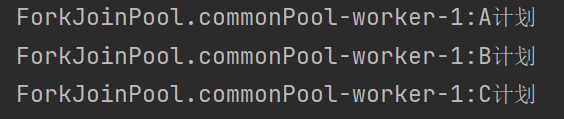
- 当第一个使用指定的异步线程池后,后面的都会使用该同一线程。
public class AsyncTaskThreadDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
CompletableFuture.runAsync(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + ":A计划");
},threadPool).thenRun(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + ":B计划");
}).thenRun(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + ":C计划");
});
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
- 当第一个使用的是自定义线程池,第二个开启了异步任务,但是没有使用自定义的线程池,那么就会使用默认的线程池
ForkJoinPool
public class AsyncTaskThreadDemo {
private static final ThreadPoolExecutor threadPool = ThreadPoolExecutorProvider.getThreadPool();
public static void main(String[] args) {
CompletableFuture.runAsync(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + ":A计划");
},threadPool).thenRunAsync(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + ":B计划");
}).thenRun(() -> {
try {
Thread.sleep(100);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + ":C计划");
});
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
10. 线程中断与LockSupport
10.1线程中断机制
10.1.1线程中断说明
线程中断机制是一种用于线程间通信和控制的机制,它允许一个线程能够请求中断另一个线程的执行,以达到控制线程的目的。
Java中的线程中断机制是通过使用中断标志来实现的,即中断标识协商机制。每个线程都有一个名为”中断标志”的布尔变量。线程中断发生时,中断标志会被设置为true。
可以通过以下方法来操作线程的中断状态:
public void interrupt(): 这个方法用于中断线程。它将线程的中断标志设置为true。但是,它并不直接停止线程的执行,而是给线程发送一个中断请求,需要在线程的逻辑中处理中断请求。public static boolean interrupted(): 这个静态方法用于检查当前线程的中断状态,并清除中断标志。如果中断标志被设置为true,则返回true;否则,返回false。public boolean isInterrupted(): 这个方法用于检查线程的中断状态,但不会清除中断标志。如果中断标志被设置为true,则返回true;否则,返回false。
需要注意的是,中断仅仅是一种线程间的协作机制,并不直接停止线程的执行。如果线程处于正常活动状态,那么会将该线程的中断标志设置为true, 不会停止线程。被设置中断标志的线程将继续正常运行,不受影响。所以,interrupt()并不能真正的中断线程,需要被调用的线程自己进行配合才行。
如果线程处于被阻塞状态(例如处于sleep, wait, join等状态),在别的线程中调用当前线程对象的interrupt方法,那么线程将立即退出被阻塞状态,中断状态被清除,并抛出一个InterruptedException异常。
如果中断不活动的线程不会产生任何影响。
10.1.2如何中断线程
10.1.2.1volatile
使用一个 volatile 标志变量:在线程的执行逻辑中,使用一个 volatile 标志变量来控制线程是否继续执行。当需要中断线程时,将标志变量设置为 false,线程会检查该标志并安全地退出。
如下:
public class volatileDemo {
private static volatile boolean flag = false;
public static void main(String[] args) {
new Thread(() -> {
while (true) {
if (flag) {
System.out.println("volatile的值被修改为ture,线程终止!");
break;
}
System.out.println(Thread.currentThread().getName() + "Hello Volatile!");
}
},"执行线程").start();
try {
Thread.sleep(20);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
new Thread(() -> {
flag = true;
},"修改线程").start();
}
}
10.1.2.2AtomicBoolean
AtomicBoolean 是 Java 中一个原子布尔变量类,可以用于在多线程环境下对布尔值进行原子操作。
public class AtomicBooleanDemo {
private static AtomicBoolean atomicBoolean = new AtomicBoolean();
public static void main(String[] args) {
new Thread(() -> {
while (true){
if (atomicBoolean.get()){
System.out.println("atomicBoolean的值被修改为ture,线程终止!");
break;
}
System.out.println(Thread.currentThread().getName() + "Hello AtomicBoolean");
}
},"执行线程").start();
try {
Thread.sleep(20);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
new Thread(() -> {
atomicBoolean.set(true);
}).start();
}
}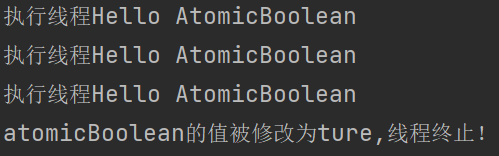
10.1.2.3interrupt
可以通过以下方法来操作线程的中断状态:
public void interrupt(): 这个方法用于中断线程。它将线程的中断标志设置为true。但是,它并不直接停止线程的执行,而是给线程发送一个中断请求,需要在线程的逻辑中处理中断请求。public static boolean interrupted(): 这个静态方法用于检查当前线程的中断状态,并清除中断标志。如果中断标志被设置为true,则返回true;否则,返回false。public boolean isInterrupted(): 这个方法用于检查线程的中断状态,但不会清除中断标志。如果中断标志被设置为true,则返回true;否则,返回false。
public class InterrnuptDemo {
public static void main(String[] args) {
Thread thread01 = new Thread(() -> {
while (true) {
if (Thread.currentThread().isInterrupted()) {
System.out.println("当前线程的中断标识被修改为ture,线程终止!");
break;
}
System.out.println(Thread.currentThread().getName() + "Hello interrupt");
}
}, "执行线程");
thread01.start();
try {
Thread.sleep(20);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
new Thread(() -> {
// 设置中断标志位
thread01.interrupt();
},"中断线程").start();
}
}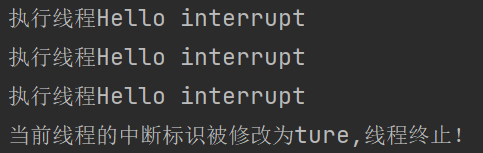
10.2线程阻塞和唤醒
10.2.1线程阻塞和唤醒的方法
- 通过 Object类的 wait/notify 方法
- 通过 Condition 的 await/signal 方法
- 通过LockSupport的park()/unpark()方法
10.2.2Object类的 wait/notify
- Object类提供了三个线程间通信的方法,wait(),notify(),notifyAll()。这三个方法必须都在同步代码块中执行的。
| 方法名 | 具体操作 |
|---|---|
| wait() | wait()方法执行前,是必须要获得对应的锁的,当执行wait()方法后,线程就会释放掉自己所占有的锁,释放CPU,然后进入阻塞状态,直到被notify()方法唤醒。对于某一个参数的版本,实现中断和虚假唤醒是可能的,而且此方法应始终在循环中使用: |
| notify() | 会唤醒一个处于等待该对象锁的线程,然后继续往下执行,直到执行完退出对象锁锁住的区域(synchronized修饰的代码块)后再释放锁。 |
| notifyAll() | 和notify()方法差不多,只不过他是唤醒所有等待该对象锁的线程,让他们进入就绪队列,但是谁执行就看谁抢占到CPU,notify()方法也是这样,只不过是唤醒随机的一个而已 |
采用通过匿名内部类的方式来实现
Runnable接口创建多线程。采用synchronized关键字来实现同步方法。通过 Object类的wait/notify方法来实现线程间通信。Oprea类:
class Oprea{ private int number = 0; public synchronized void add() throws InterruptedException { while (number != 0){ this.wait(); } number++; System.out.println(Thread.currentThread().getName() + "::" + number); this.notifyAll(); } public synchronized void minus() throws InterruptedException { while (number == 0){ this.wait(); } number--; System.out.println(Thread.currentThread().getName() + "::" + number); this.notifyAll(); } }ThreadCommouication类:
public class ThreadCommouication { public static void main(String[] args) { Oprea oprea = new Oprea(); new Thread(() -> { for (int i = 0; i < 5; i++) { try { oprea.add(); } catch (InterruptedException e) { throw new RuntimeException(e); } } },"线程01").start(); new Thread(() -> { for (int i = 0; i < 5; i++) { try { oprea.minus(); } catch (InterruptedException e) { throw new RuntimeException(e); } } },"线程02").start(); } }存在的问题
wait(),notify()、notifyAll()这三个方法必须都在同步代码块中执行,并且成对出现。同时必须先wait(),后notify(),notifyAll()。
10.2.3Condition 的 await/signal
- Condiction对象是通过
lock对象来创建得(调用lock对象的newCondition()方法),他在使用前也是需要获取锁得,其中,Lock 替代了 synchronized 方法和语句的使用,Condition 替代了 Object 监视器方法的使用。Condiction对象得常用方法:
- await() : 线程自主释放锁,进入沉睡状态,直到被再次唤醒。
- await(long time, TimeUnit unit) :线程自主释放锁,进入沉睡状态,被唤醒或者未到达等待时间时一直处于等待状态。
- signal(): 唤醒一个等待线程。
- signal()All() :唤醒所有等待线程,能够从等待方法返回的线程必须获得与Condition相关的锁。
采用通过匿名内部类的方式来实现
Runnable接口创建多线程。采用Lock接口的实现类ReentrantLock来实现线程间互斥。通过 Condition 的await/signalAll方法来实现线程间通信。Oprea类:
class Oprea { private int number = 0; private ReentrantLock lock = new ReentrantLock(); private Condition condition = lock.newCondition(); public void add(){ lock.lock(); try { while (number != 0) { condition.await(); } number++; System.out.println(Thread.currentThread().getName() + "::" + number); condition.signalAll(); } catch (InterruptedException e) { throw new RuntimeException(e); } finally { lock.unlock(); } } public void minus() { lock.lock(); try { while (number == 0) { condition.await(); } number--; System.out.println(Thread.currentThread().getName() + "::" + number); condition.signalAll(); } catch (Exception e) { throw new RuntimeException(e); } finally { lock.unlock(); } } }ThreadCommouication类:
public class ThreadCommunication { public static void main(String[] args) { Oprea oprea = new Oprea(); new Thread(() -> { for (int i = 0; i < 5; i++) { oprea.add(); } }, "线程01").start(); new Thread(() -> { for (int i = 0; i < 5; i++) { oprea.minus(); } }, "线程02").start(); } }存在的问题和Object类中的
wait()、notify()相同。即线程必须先持有锁。并且先等待后在唤醒。
10.2.4LockSupport的park()/unpark()
LockSupport 类是 Java 提供的一个线程同步工具类,所有的方法都是静态方法,用于实现线程的阻塞和唤醒操作。它提供了一种比 Object 类的 wait() 和 notify() 方法更灵活和底层的方式来控制线程的暂停和恢复,即可以让线程在任意位置阻塞,阻塞后也有相对应的唤醒机制。
LockSupport 类主要提供了以下几种方法:
park(): 用于使当前线程暂停,类似于Thread.sleep()方法,但是与sleep()方法相比,park()方法不需要指定固定的时间,可以在任何时候被其他线程唤醒。park(Object blocker): 与上述方法类似,但可以指定一个对象作为阻塞器,用于更好地监视和分析线程的阻塞情况。unpark(Thread thread): 用于唤醒指定的线程。如果该线程之前由于调用了park()方法而被暂停,则会解除其阻塞状态;如果线程之前没有调用过park()方法,则下一次调用park()方法时不会被暂停。
LockSupport的unpark()方法可以理解为给线程提供一个凭证,使得该线程在后续调用park()时可以立即返回而不会阻塞。unpark()可以唤醒被park()阻塞的线程。线程最多只能持有一个凭证。需要注意的是,
unpark()方法的调用可以在park()方法之前或之后,没有顺序要求。即使在park()之前调用unpark(),线程调用park()时也不会阻塞,因为已经有了凭证。
LockSupport 类的使用一般与其他同步器(如 Lock、Condition 等)搭配使用,用于实现更复杂的线程同步和通信机制。它是非常底层的工具类,其调用的是Unsafe中的native方法。
案例:
- 如下,无锁的结构,即不需要在代码块中使用
park()和unpark()方法。
public class LockSupportDemo {
public static void main(String[] args) {
Thread thread01 = new Thread(() -> {
// 阻塞线程
LockSupport.park();
System.out.println("线程被唤醒,执行");
}, "执行线程");
thread01.start();
new Thread(() -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 唤醒线程
LockSupport.unpark(thread01);
}, "唤醒线程").start();
}
}
- 先唤醒再阻塞,依然能够从阻塞中被唤醒。
public class LockSupportDemo {
public static void main(String[] args) {
Thread thread01 = new Thread(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 阻塞线程
LockSupport.park();
System.out.println("线程被唤醒,执行");
}, "执行线程");
thread01.start();
new Thread(() -> {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
// 唤醒线程
LockSupport.unpark(thread01);
}, "唤醒线程").start();
}
}
11.JMM(Java内存模型)
11.1JMM简介
JMM 是Java内存模型( Java Memory Model),简称JMM。JMM本身是一种抽象的概念并不真实存在,它仅仅描述的是一组约定或规范。JMM定义了在多线程环境下,共享内存的访问方式和操作规则。它定义了线程之间如何通过共享内存进行通信,并确保不同线程之间的可见性、原子性和有序性。JMM保证在不同的编译器和处理器平台上,程序的行为都是一致的。
11.2JMM的3大特性
- 可见性(Visibility):JMM保证在一个线程对
共享变量的修改对其他线程是可见的。当一个线程修改了一个共享变量的值,JMM会将该值同步到主内存中,并强制其他线程从主内存中读取最新的值,以保证对共享变量的修改能够被其他线程观察到。- 原子性(Atomicity):JMM提供了对基本类型以及引用的原子读写操作。原子操作是不可中断的单个操作,要么全部执行成功,要么不执行。在JMM中,原子操作能够保证线程之间的原子性,防止多个线程同时修改同一个共享变量导致的数据不一致问题。
- 有序性(Ordering):JMM保证程序的执行顺序与代码的编写顺序一致。在JMM中,通过happens-before关系来指定操作之间的顺序。如果操作A happens-before操作B,那么操作A的执行结果对于操作B来说是可见的。happens-before关系可以通过同步操作(如锁和volatile变量的读写)来建立。
11.2.1可见性(Visibility)
可见性(Visibility):JMM保证在一个线程对共享变量的修改对其他线程是可见的。当一个线程修改了一个共享变量的值,JMM会将该值同步到主内存中,并强制其他线程从主内存中读取最新的值,以保证对共享变量的修改能够被其他线程观察到。
系统中主内存共享变量数据修改被写入的时机是不确定的,多线程并发下很可能出现“脏读”,所以每个线程都有自己的工作内存,线程自己的工作内存中保存了该线程使用到的变量的主内存副本拷贝,线程对变量的所有操作(读取、赋值等)都必须在线程自己的工作内存中进行,而不能够直接写入主内存中的变量,不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
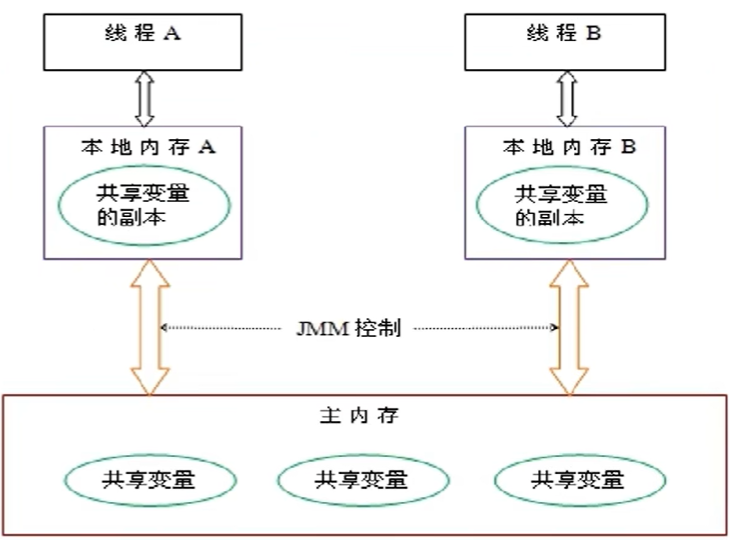
11.2.2原子性(Atomicity)
原子性(Atomicity):JMM提供了对基本类型以及引用的原子读写操作。原子操作是不可中断的单个操作,要么全部执行成功,要么不执行。在JMM中,原子操作能够保证线程之间的原子性,防止多个线程同时修改同一个共享变量导致的数据不一致问题。
11.2.3有序性(Ordering)
有序性(Ordering):JMM保证程序的执行顺序与代码的编写顺序一致。在JMM中,通过happens-before关系来指定操作之间的顺序。如果操作A happens-before操作B,那么操作A的执行结果对于操作B来说是可见的。happens-before关系可以通过同步操作(如锁和volatile变量的读写)来建立。
但为了提升性能,编译器和处理器通常会对指令序列进行重新排序。Java规范规定JVM线程内部维持顺序化语义,即只要程序的最终结果与它顺序执行的结果相等,那么指令的执行顺序可以与代码顺序不一致,此过程叫指令的重排序。
11.3多线程对变量的读写过程
由于JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有的地方成为栈空间),工作内存是每个线程的私有数据区域,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读写赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝到线程自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,各个线程中的工作内存存储着主内存中的变量副本拷贝,因此不同的线程无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成,其简要访问过程如下图:
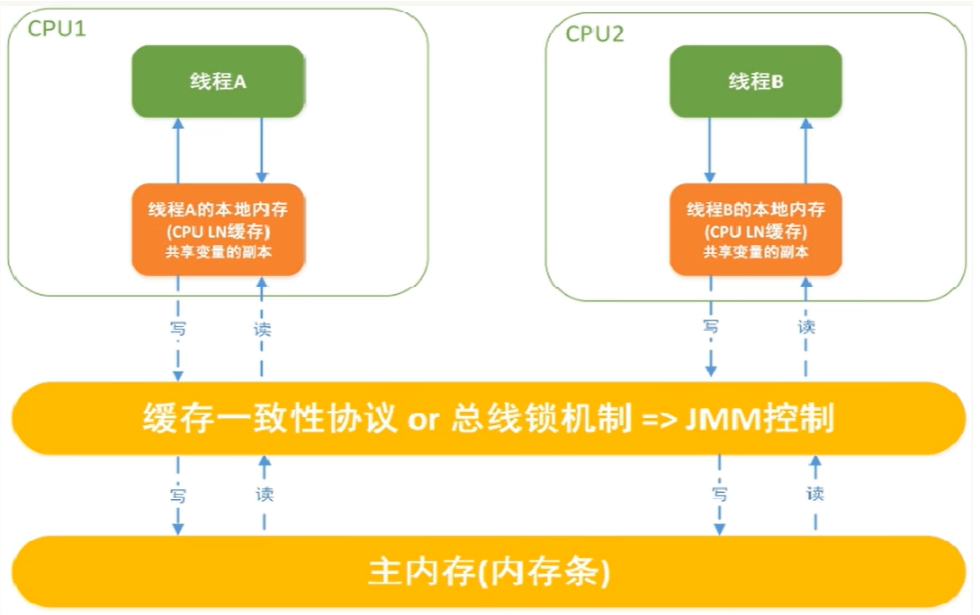
11.4多线程先行发生原则happens-before
11.4.1先行发生原则happens-before概述
在JMM中,如果一个操作执行的结果需要对另一个操作可见或者代码重排序,那么这两个操作之间必须存在happens-before(先行发生)原则。逻辑上的先后关系。
如:
| x=5 | 线程A执行 |
|---|---|
| y=x | 线程B执行 |
y是否等于5呢?
如果线程A的操作(x=5)
happens-before(先行发生)线程B的操作(y=x),那么可以确定线程B执行y=5一定成立;如果他们不存在happens-before原则,那么y=5不一定成立
这就是happens-before原则的为例———–>包含可见性和有序性的约束
happens-before(先行发生)原则是判断数据是否存在竞争,线程是否安全的非常有用的手段。
总结:
如果一个操作
happens-before(先行发生)另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。两个操作之间存在
happens-before关系,并不意味着一定要按照happens-before原则制定的顺序来执行。如果指令重排序之后的执行结果与按照happens- before关系来执行的结果一致,那么这种重排序并不非法。
例如:
周一张三周二李四,假如有事情调换班可以的。1+2+3= 3+2+1
11.4.2happens-before之8条
从JDK 5开始,Java使用新的JSR-133内存模型,提供了 happens-before 原则来辅助保证程序执行的原子性、可见性以及有序性的问题,它是判断数据是否存在竞争、线程是否安全的依据,happens-before 原则内容如下:
次序规则:一个线程内,按照代码的顺序,写在前面的操作先行发生于写在后面的操作,也就是说前一个操作的结果可以被后续的操作获取(保证语义串行性,按照代码顺序执行)。比如前一个操作把变量x赋值为1,那后面一个操作肯定能知道x已经变成了1
锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作(后面指时间上的先后)。
volatile变量规则:对一个volatile变量的写操作先行发生于后面对这个变量的读操作,前面的写对后面的读是可见的,这里的后面同样指时间上的先后
传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C。
线程启动规则(Thread start Rule):Thread对象的start()方法先行发生于此线程的每一个动作
线程中断规则(Thread Interruption Rule):
- 对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 可以通过Thread.interrupted()检测到是否发生中断
- 也就是说你要先调用interrupt()方法设置过中断标志位,我才能检测到中断发生
线程终止规则(Thread Termination Rule):线程中的所有操作都优先发生于对此线程的终止检测,我们可以通过isAlive()等手段检测线程是否已经终止执行。
对象终结规则(Finalizer Rule):一个对象的初始化完成(构造函数执行结束)先行发生于它的
finalize()方法的开始——->对象没有完成初始化之前,是不能调用finalized()方法的
11.4.3happens-before小总结
在Java语言里面,
Happens-before的语义本质上是一种可见性A happens-before B ,意味着A发生过的事情对B而言是可见的,无论A事件和B事件是否发生在同一线程里
JVM的设计分为两部分:
- 一部分是面向我们程序员提供的,也就是happens-before规则,它通俗易懂的向我们程序员阐述了一个强内存模型,我们只要理解happens-before规则,就可以编写并发安全的程序了
- 另一部分是针对JVM实现的,为了尽可能少的对编译器和处理器做约束从而提升性能,JMM在不影响程序执行结果的前提下对其不做要求,即允许优化重排序,我们只要关注前者就好了,也就是理解happens-before规则即可,其他繁杂的内容由JMM规范结合操作系统给我们搞定,我们只写好代码即可。
11.4.4案例分析
private int value =0;
public int getValue(){
return value;
}
public int setValue(){
return ++value;
}问题描述:假设存在线程A和B,线程A先(时间上的先后)调用了setValue()方法,然后线程B调用了同一个对象的getValue()方法,那么线程B收到的返回值是什么?
答案:不一定
分析happens-before规则(规则5,6,7,8可以忽略,和代码无关)
- 由于两个方法由不同线程调用,不满足一个线程的条件,不满足程序次序规则
- 两个方法都没有用锁,不满足锁定规则
- 变量没有使用volatile修饰,所以不满足volatile变量规则
- 传递规则为A->B,B->C,A->C,所以传递原则也不满足
综上:无法通过
happens-before原则推导出线程A happens-before 线程B,虽然可以确定时间上线程A优于线程B,但就是无法确定线程B获得的结果是什么,所以这段代码不是线程安全的注意:
- 如果两个操作的执行次序无法从happens-before原则推导出来,那么就不能保证他们的有序性,虚拟机可以随意对他们进行重排序
如何修复?
- 把getter/setter方法都定义为synchronized方法——->不好,重量锁,并发性下降
private int value =0;
public synchronized int getValue(){
return value;
}
public synchronized int setValue(){
return ++value;
}- 把value定义为volatile变量,由于setter方法对value的修改不依赖value的原值,满足volatile关键字使用场景
/**
* 利用volatile保证读取操作的可见性,
* 利用synchronized保证符合操作的原子性结合使用锁和volatile变量来减少同步的开销
*/
private volatile int value =0;
public int getValue(){
return value;
}
public synchronized int setValue(){
return ++value;
}-
12.volatile
12.1内存屏障Memory Barrier
12.1.1内存屏障概述
内存屏障(Memory Barrier),也称为内存栅栏或内存屏障指令,用于限制指令重排和控制内存访问的顺序。
在多线程编程中,内存屏障是确保数据一致性和避免竞态条件的关键机制。由于现代处理器的特性,为了提高性能,它们可能会对指令进行重排,包括对内存访问的重排。这可能导致在线程之间共享的变量的值不一致或出现意料之外的结果。
内存屏障之前的所有写操作都要回写到主内存
内存屏障之后的所有读操作都能获得内存屏障之前的所有写操作的最新结果(实现了可见性)。
在 Java 中,volatile 关键字实际上具有读屏障和写屏障的效果,它提供了一种简单的方式来确保线程之间的数据一致性。
12.1.1内存屏障类型
- 按两种屏障划分
- 写屏障(Write Barrier):将写操作刷新到内存,并清空处理器的写缓冲区。这样可以确保其他处理器或线程在读取该变量时能够看到最新的写入值。
- 读屏障(Read Barrier):强制处理器确保读操作从内存中读取最新的值,而不是使用缓存中的旧值。这样可以确保读取操作获取到最新的数据,而不是过时的数据。
- 按四种屏障划分
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad | Load1;LoadLoad;Load2 | 保证Load1的读取操作在Load2及后续读取操作之前执行 |
| StoreStore | Store1;StoreStore;Store2 | 在store2及其后的写操作执行前,保证Store1的写操作已经刷新到主内存 |
| LoadStore | Load1;LoadStore;Store2 | 在Store2及其后的写操作执行前,保证Load1的读操作已经结束 |
| StoreLoad | Store1;StoreLoad;Load2 | 保证Store1的写操作已经刷新到主内存后,Load2及其后的读操作才能执行 |
12.2volatile概述
volatile 是 Java 中的关键字,用于声明在多线程环境中访问的变量。
当一个变量被声明为 volatile 时,它具有以下特性:
- 可见性(Visibility):在一个线程中对
volatile变量的修改,对其他线程是可见的。当一个线程修改了volatile变量的值,其他线程会立即看到最新的值,而不是使用缓存中的旧值。- 禁止指令重排(Prevent Instruction Reordering):
volatile关键字禁止编译器对被声明为volatile的变量的读写操作进行指令重排优化。这样可以确保变量的读写操作按照程序中的顺序执行,避免了可能的线程安全问题。
但需要注意的是,volatile 并不能保证复合操作的原子性。即使 volatile 修饰的变量在单独的操作中是原子的,多个操作组合起来仍可能出现竞态条件(race condition)。如果需要确保多个操作的原子性,可以考虑使用 synchronized 关键字或使用 java.util.concurrent.atomic 包下的原子类。
内存语义:
- 当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值立即刷新回主内存中
- 当读一个volatile变量时,JMM会把该线程对应的本地内存设置为无效,重新回到主内存中读取最新共享变量的值
- 所以volatile的写内存语义是直接刷新到主内存中,读的内存语义是直接从主内存中读取
volatile凭什么可以保证可见性和有序性?
- 内存屏障
Memory Barrier
- 内存屏障
12.3volatile的可见性
volatile的可见性可以保证写操作时被volatile修饰的共享变量的值会立即更新到主内存。读操作时会读取到被volatile修饰的共享变量的最新值。
如下:
- 当不对变量添加
volatile时,不能够保证变量在不同线程之间的可见性。
为什么线程thread01不能够获取到最新的变量值:
- 主线程修改了flag之后没有将其刷新到主内存,所以thread01线程看不到。
- 主线程将flag刷新到了主内存,但是thread01一直读取的是自己工作内存中flag的值,没有去主内存中更新获取flag最新的值。
public class VolatileDemo {
static boolean flag = true;
public static void main(String[] args) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "开始执行!");
while (flag){
}
System.out.println("flag被修改为false,线程终止!");
},"Thread01").start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
new Thread(() -> {
flag = false;
System.out.println(Thread.currentThread().getName() + "将flag修改为false!");
},"Thread02").start();
}
}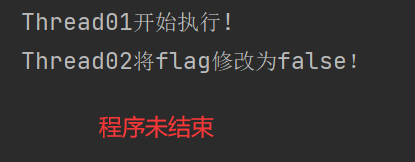
- 将
flag声明为volatile可以确保任何一个线程修改了flag的值后,其他线程能够立即看到最新的值
public class VolatileDemo {
static volatile boolean flag = true;
public static void main(String[] args) {
new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "开始执行!");
while (flag){
}
System.out.println("flag被修改为false,线程终止!");
},"Thread01").start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
new Thread(() -> {
flag = false;
System.out.println(Thread.currentThread().getName() + "将flag修改为false!");
},"Thread02").start();
}
}
13.4volatile禁止指令重排
13.4.1指令重排的概念
指令重排是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段,有时候会改变程序语句的先后顺序。但重排后的指令绝对不能改变原有的串行语义!
不存在数据依赖关系,可以重排序;
存在数据依赖关系,禁止重排序
- 不存在数据依赖性,可以指令重排
重排前:
int a = 1;
int b = 2;
int c = a + b重排后:
int b = 2;
int a = 1;
int c = a + b13.4.2volatile禁止指令重排行为
- 当第一个操作为voltile读时, 不论第二个操作是什么,都不能重排序。这个操作保证了volatile读之后的操作不会被重排到volatile读之前。
- 当第二个操作为volatile写时, 不论第一 个操作是什么,都不能重排序。这个操作保证了volatile写之前的操作不会被重排到volatile写之后。
- 当第一个操作为volatile写时, 第二个操作为volatile读时, 不能重排。

再看内存屏障的四种类型:
| 屏障类型 | 指令示例 | 说明 |
|---|---|---|
| LoadLoad | Load1;LoadLoad;Load2 | 保证Load1的读取操作在Load2及后续读取操作之前执行 |
| StoreStore | Store1;StoreStore;Store2 | 在store2及其后的写操作执行前,保证Store1的写操作已经刷新到主内存 |
| LoadStore | Load1;LoadStore;Store2 | 在Store2及其后的写操作执行前,保证Load1的读操作已经结束 |
| StoreLoad | Store1;StoreLoad;Load2 | 保证Store1的写操作已经刷新到主内存后,Load2及其后的读操作才能执行 |
在每一个volatile读操作后面插入一个LoadLoad屏障,LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。
在每一个volatile读操作后面插入一个LoadStore屏障,LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。
在每一个volatile写操作前面插入一个StoreStore屏障,StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作都已经刷新到主内存
在每一个volatile写操作后面插入一个StoreLoad屏障,StoreLoad屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序
13.4.3案例说明
public class VolatileMemoryBarrier {
int i = 0;
volatile boolean flag = false;
public void write(){
i = 2;
flag = true;
}
public void read(){
if (flag){
System.out.println(i);
}
}
}

13.5volatile不具有原子性
volatile 关键字并不能保证原子性。虽然 volatile 可以确保可见性,即在一个线程中对 volatile 变量的修改对其他线程是可见的,但它并不能保证对 volatile 变量的读取和写入是原子操作。即volatile解决多线程内存不可见问题。对于一写多读,是可以解决变量同步问题,但是如果多写,同样无法解决线程安全问题。
原子性是指一个操作要么完全执行,要么完全不执行,没有中间状态。而 volatile 只能保证可见性,不能保证操作的原子性。即使声明了 volatile,在多个线程同时对同一个 volatile 变量进行写操作时,最终的结果仍然可能是不确定的。
对于volatile变量,JVM只是保证从主内存加载到线程工作内存的值是最新的,也只是数据加载时是最新的。
如果第2个线程在第1个线程读取旧值和写回新值期间读取共享变量,也就造成了线程安全问题。
要保证操作的原子性,通常需要使用同步机制,例如使用锁或原子类。Java 中的 synchronized 关键字和 java.util.concurrent 包中的原子类(如 AtomicInteger、AtomicLong 等)可以实现原子操作。
- 使用
volatile修改线程共享变量,查看是否存在原子性
class Add{
volatile int number = 0;
public void add(){
number++;
}
}
public class VolatileAtomicDemo {
public static void main(String[] args) {
Add add = new Add();
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
add.add();
}
}).start();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(add.number);
}
}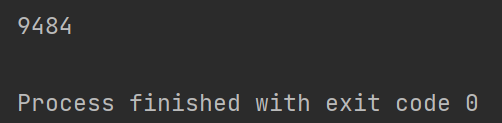
- 使用
synchronized来实现同步机制,保证原子性
class Add {
int number = 0;
public synchronized void add() {
number++;
}
}
public class VolatileAtomicDemo {
public static void main(String[] args) {
Add add = new Add();
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
add.add();
}
}).start();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(add.number);
}
}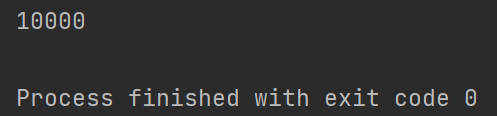
总结:volatile虽然可以保证可见性,但是因为整个自增的操作不是原子性的,还是会出现同步不及时,导致线程安全的问题,所以要加上synchronied保证自增操作串行化。
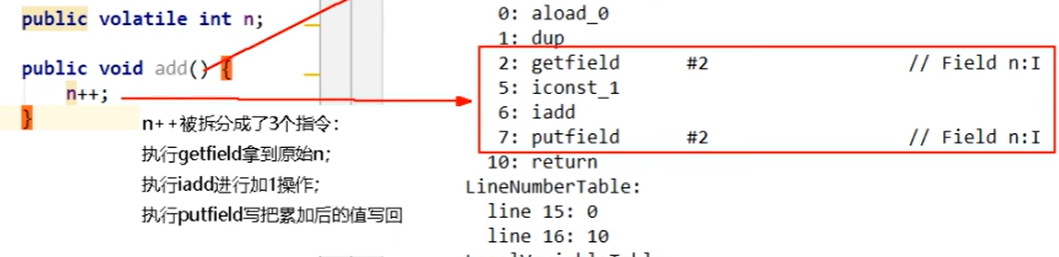
13.6volatile的使用
- 单一赋值可以,但是含复合运算赋值不可以(i++之类的)
- volatile int a = 10;
- volatile boolean flag = true;
- 状态标志,判断业务是否结束
- 作为一个布尔状态标志,用于指示发生了一个重要的一次性事件,例如完成初始化或任务结束
- 开销较低的读,写锁策略
- 当读远多于写,结合使用内部锁和volatile变量来减少同步的开销
- 原理是:利用volatile保证读操作的可见性,利用synchronized保证符合操作的原子性
public class Student{
private volatile int age;
public int getAge() {
return age;
}
public synchronized void setAge(int age) {
this.age = age;
}
}- DCL双端锁的发布
- 问题描述:首先设定一个加锁的单例模式场景
13.CAS
13.1CAS概述
CAS是”Compare and Swap”(比较并交换)的缩写,是一种并发编程中常用的原子操作。CAS操作包含了三个参数:
- 需要被修改的内存引用
- 期望的值
- 新值
它的基本思想是,如果内存引用的值与期望的值相等,那么就将新值写入该内存位置;否则,不做任何操作或者重试,其中重试机制就被称为自旋。

public class CASDemo {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(10);
System.out.println(atomicInteger.compareAndSet(10,2023) + " " + atomicInteger.get());
System.out.println(atomicInteger.compareAndSet(10,2024) + " " + atomicInteger.get());
}
}
13.2unSafe类
Unsafe类是Java中用于实现CAS操作的核心类之一。它提供了一系列底层的操作方法,可以直接操作内存和对象,用来实现对共享变量的原子操作。
在CAS操作中,Unsafe类的主要作用是提供了compareAndSwap系列的方法,如compareAndSwapInt、compareAndSwapLong,用于执行比较并交换的操作。这些方法底层直接使用了硬件层面的CAS指令,通过修改内存中的值来实现对共享变量的原子操作。
CAS并发原语体现在Java语言中就是sun.misc.Unsafe类中的各个方法。调用Unsafe类中的CAS方法,JVM会帮我们实现出CAS汇编指令。这是一种完全依赖于硬件的功能,通过它实现了原子操作。再次强调,由于CAS是一种系统原语,原语属于操作系统用语范畴,是由若干条指令组成的,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条CPU的原子指令,不会造成所谓的数据不一致问题。
13.3CAS实现自旋锁
- 自旋锁概述
CAS是实现自旋锁的基础,CAS利用CPU指令保证了操作的原子性,以达到锁的效果,至于自旋锁,字面意思自己旋转。是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,当线程发现锁被占用时,会不断循环判断锁的状态,直到获取。这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
- 案例
如下案例就是采用原子引用(在14.3章节引用类型原子类)的方式。线程A首先获取到锁并且不释放,线程A阻塞3s,同时线程B尝试获取到锁,由与线程B获取到锁的时候,内存引用的值“线程A”和所期望的值“线程B”不相符,所以自旋。直到线程A释放锁。
public class SpinLockDemo {
AtomicReference<Thread> atomicReference = new AtomicReference<>();
public void lock(){
System.out.println("线程" + Thread.currentThread().getName() + "获取锁");
while (!atomicReference.compareAndSet(null,Thread.currentThread())){
}
}
public void unlock(){
atomicReference.compareAndSet(Thread.currentThread(),null);
System.out.println("线程" + Thread.currentThread().getName() + "释放锁");
}
public static void main(String[] args) {
SpinLockDemo spinLockDemo = new SpinLockDemo();
new Thread(() -> {
spinLockDemo.lock();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
spinLockDemo.unlock();
},"线程A").start();
new Thread(() -> {
spinLockDemo.lock();
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
spinLockDemo.unlock();
},"线程B").start();
}
}
13.4CAS的缺点
CAS (Compare and Swap) 作为一种实现原子操作的机制,具有以下一些缺点:
- 自旋消耗CPU资源:使用CAS实现自旋锁时,如果锁已被其他线程占用,当前线程会一直自旋等待,不断尝试获取锁。这样会导致CPU资源被浪费,特别是在高并发场景下,自旋等待的线程会占用大量的CPU时间。
- ABA问题:CAS操作只能保证变量的值在操作时是否发生了变化,但无法检测变量的值在操作过程中发生了何种变化。例如,线程 A 将变量的值从 A 修改为 B,然后再修改为 A,而线程 B 在比较时发现变量的值仍然是 A,认为变量未被修改。这种情况下,CAS可能会误判变量未被修改,导致数据一致性问题。
- 循环时间长开销大:使用CAS操作时,如果竞争非常激烈,每次都要进行一次比较和交换可能会导致循环等待的时间非常长,严重影响性能。
- 只能保证一个共享变量的原子操作:CAS只能保证一个共享变量的原子操作,无法保证多个共享变量之间操作的原子性。当需要保证多个共享变量之间的一致性时,需要使用其他机制来保证。
虽然CAS有一些缺点,但在某些场景下仍然是一种有效的机制,特别是在低竞争、并发性较低景下,CAS可以提供高效的原子操作。在高竞争、高并发的场景下,可以考虑使用其他锁机制,如互斥锁(Mutex)或读写锁(ReadWriteLock)等。
13.5ABA问题的解决
可以采用版本号机制来解决ABA问题
版本号机制:在每次变量的修改操作中引入版本号,即在变量的值上同时记录一个版本号。每次修改时,不仅比较变量的值是否与期望值相等,还需要比较版本号是否一致。这样,在ABA问题出现时,由于版本号已经变化,CAS操作可以正确地判断变量是否被修改。
AtomicStampedReference(在14.3章节引用类型原子类) 是 java.util.concurrent.atomic 包下的一个类,它用于解决并发编程中的 ABA 问题。
AtomicStampedReference 类内部维护了两个值,一个是引用类型的共享变量的值,另一个是用于记录版本号的整数值。它通过比较共享变量和版本号同时满足的条件,来判断共享变量是否被其他线程修改过。
AtomicStampedReference 提供了以下常用方法:
getReference():获取当前共享变量的值。getStamp():获取当前版本号的值。compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp):如果当前共享变量的值等于expectedReference并且版本号等于expectedStamp,则将共享变量的值更新为newReference,版本号更新为newStamp。如果更新成功,返回 true;否则返回 false。attemptStamp(V expectedReference, int newStamp):如果当前共享变量的值等于expectedReference,则尝试将版本号更新为newStamp。如果更新成功,返回 true;否则返回 false。
通过使用 AtomicStampedReference 类,可以在 CAS 操作时额外考虑版本号的变化,从而解决 ABA 问题,确保共享变量的正确性和一致性。
案例:
public class AtomicStampedReferenceDemo {
public static void main(String[] args) {
String str1 = "字符串1";
AtomicStampedReference<String> sasr = new AtomicStampedReference<>(str1, 1);
new Thread(() -> {
int stamp = sasr.getStamp();
System.out.println("线程A首次内容:" + sasr.getReference() + ",版本号:" + stamp);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
sasr.compareAndSet(str1, "字符串2", sasr.getStamp(), sasr.getStamp() + 1);
System.out.println("线程A第二次内容:" + sasr.getReference() + ",版本号:" + sasr.getStamp());
sasr.compareAndSet("字符串2", str1, sasr.getStamp(), sasr.getStamp() + 1);
System.out.println("线程A第三次内容:" + sasr.getReference() + ",版本号:" + sasr.getStamp());
}).start();
new Thread(() -> {
int stamp = sasr.getStamp();
System.out.println("线程B首次内容:" + sasr.getReference() + ",版本号:" + stamp);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(sasr.compareAndSet(str1, "字符串2", stamp, stamp + 1));
System.out.println("查看当前内容:" + sasr.getReference() + ",版本号:" + sasr.getStamp());
}).start();
}
}
14.原子操作类
Atomic 翻译成中文是原子的意思。 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
14.1 基本类型原子类
14.1.1基本类型
AtomicInteger:整型原子类AtomicBoolean:布尔型原子类AtomicLong:长整型原子类
常用API
public final int get() //获取当前的值
public final int getAndSet(int newValue)//获取当前的值,并设置新的值
public final int getAndIncrement()//获取当前的值,并自增
public final int getAndDecrement() //获取当前的值,并自减
public final int getAndAdd(int delta) //获取当前的值,并加上预期的值
boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将该值设置为输入值(update)
public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。14.1.2案例
为了防止在并发线程为执行完之前,main线程就已经结束,导致计算提前结束,可以采用CountDownLatch来等到多线程执行完毕。
public class AtomicIntegerDemo {
private static final int number = 10;
// 创建原子整型类
private static AtomicInteger atomicInteger = new AtomicInteger(0);
public static void main(String[] args) {
// 创建CountDownLatch类,用于等待所有线程执行完毕
CountDownLatch countDownLatch = new CountDownLatch(number);
for (int i = 0; i < number; i++) {
new Thread(() -> {
try {
for (int j = 0; j < 100; j++) {
atomicInteger.getAndIncrement();
}
} finally {
countDownLatch.countDown();
}
}).start();
}
try {
// 等待所有线程执行完毕
countDownLatch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("最终结果:" + atomicInteger.get());
}
}

14.2 数组类型原子类
14.2.1基本类型
AtomicIntegerArray:整型数组原子类AtomicLongrArray:长整型数组原子类AtomicReferenceArray:用类型数组原子类
常用API:
public final int get(int i) //获取 index=i 位置元素的值
public final int getAndSet(int i, int newValue)//返回 index=i 位置的当前的值,并将其设置为新值:newValue
public final int getAndIncrement(int i)//获取 index=i 位置元素的值,并让该位置的元素自增
public final int getAndDecrement(int i) //获取 index=i 位置元素的值,并让该位置的元素自减
public final int getAndAdd(int i, int delta) //获取 index=i 位置元素的值,并加上预期的值
boolean compareAndSet(int i, int expect, int update) //如果输入的数值等于预期值,则以原子方式将 index=i 位置的元素值设置为输入值(update)
public final void lazySet(int i, int newValue)//最终 将index=i 位置的元素设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。14.2.2案例
public class AtomicArrayDemo {
public static void main(String[] args) {
AtomicIntegerArray atomicIntegerArray = new AtomicIntegerArray(new int[]{1, 2, 3});
boolean result = atomicIntegerArray.compareAndSet(0, 1, 100);
System.out.println("修改是否成功:" + result + ",修改后的数组:" + atomicIntegerArray.toString());
}
}
14.3引用类型原子类
14.3.1基本类型
AtomicReference:引用类型原子类AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。- 解决修改过几次
AtomicMarkableReference:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来- 解决是否修改过,它的定义就是将标记戳简化为true/false,类似于一次性筷子
14.3.2AtomicReference
原子引用(AtomicReference)是Java中的一个原子类,用于实现对引用类型变量的原子操作。它提供了一系列方法,可以实现对引用类型变量进行原子性的更新和读取操作,避免多线程环境下的并发问题。
原子引用类的主要作用是提供了compareAndSet方法,它使用CAS(Compare and Swap)操作来实现原子性的更新操作。compareAndSet方法接受两个参数,第一个参数是期望的值,第二个参数是要更新的新值。如果当前引用的值与期望的值相等,就将引用的值设置为新值,并返回true,否则返回false。
原子引用类在多线程编程中非常有用,可以用于实现一些需要保证原子性的操作,如单例模式、全局变量的更新等。它能够提供高效且线程安全的操作,避免了使用锁机制时可能引入的开销和死锁等问题。
需要注意的是,虽然原子引用类能够保证单个操作的原子性,但在多个操作之间并不能保证原子性。对于一些需要保持多个操作的原子性的场景,可以考虑使用锁机制或其他并发控制手段来实现。此外,由于原子引用类对引用对象本身是原子性操作,但对象内部的属性并不具备原子性,如果需要保证对象属性的原子性,需要进行额外的处理或使用其他的原子类。
class User{
private int age;
private String name;
public User(int age, String name) {
this.age = age;
this.name = name;
}
@Override
public String toString() {
return "User{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
public class AtomicReferenceDemo {
public static void main(String[] args) {
// 创建User原子引用类
AtomicReference<User> userAtomicReference = new AtomicReference<>();
User user1 = new User(18,"张三");
User user2 = new User(19,"李四");
// 设置userAtomicReference的值为user1
userAtomicReference.set(user1);
// 比较userAtomicReference的值是否为user1,如果是则将userAtomicReference的值设置为user2
userAtomicReference.compareAndSet(user1,user2);
System.out.println(userAtomicReference.get().toString());
}
}
14.3.3AtomicStampedReference
AtomicStampedReference 类内部维护了两个值,一个是引用类型的共享变量的值,另一个是用于记录版本号的整数值。它通过比较共享变量和版本号同时满足的条件,来判断共享变量是否被其他线程修改过。
AtomicStampedReference 提供了以下常用方法:
getReference():获取当前共享变量的值。getStamp():获取当前版本号的值。compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp):如果当前共享变量的值等于expectedReference并且版本号等于expectedStamp,则将共享变量的值更新为newReference,版本号更新为newStamp。如果更新成功,返回 true;否则返回 false。attemptStamp(V expectedReference, int newStamp):如果当前共享变量的值等于expectedReference,则尝试将版本号更新为newStamp。如果更新成功,返回 true;否则返回 false。
通过使用 AtomicStampedReference 类,可以在 CAS 操作时额外考虑版本号的变化,从而解决 ABA 问题,确保共享变量的正确性和一致性。
案例:可以使用AtomicStampedReference来解决CAS的ABA问题
public class AtomicMarkableReferenceDemo {
public static void main(String[] args) {
String str1 = "字符串1";
AtomicMarkableReference<String> sasr = new AtomicMarkableReference<>(str1, false);
new Thread(() -> {
boolean marked = sasr.isMarked();
System.out.println("线程A首次内容:" + sasr.getReference() + ",标记:" + marked);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
sasr.compareAndSet(str1, "字符串2", marked, !marked);
System.out.println("线程A第二次内容:" + sasr.getReference() + ",标记:" + sasr.isMarked());
}).start();
new Thread(() -> {
boolean marked = sasr.isMarked();
System.out.println("线程B首次内容:" + sasr.getReference() + ",标记:" + marked);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(sasr.compareAndSet(str1, "字符串2", marked, !marked));
System.out.println("查看当前内容:" + sasr.getReference() + ",标记:" + sasr.isMarked());
}).start();
}
}
14.3.3AtomicMarkableReference
AtomicMarkableReference是Java中提供的一个类,用于在引用和布尔标记之上执行原子操作。它用于并发编程中解决ABA问题,即多个线程对值进行修改,以一种对一个线程来说似乎没有改变的方式进行修改,导致错误的行为。
AtomicMarkableReference类提供了以下常用方法:
getReference():获取当前引用的值。get(boolean[] markHolder):获取当前引用的值和标记的值。
- 参数:markHolder - 用于存储标记的布尔数组。
- 作用:返回当前引用的值,并将标记值存储在传入的布尔数组中。
set(V newReference, boolean newMark):设置引用和标记的新值。
- 参数:newReference - 要设置的新引用值,newMark - 要设置的新标记值。
- 作用:将引用和标记的值设置为新的指定值。
compareAndSet(V expectedReference, V newReference, boolean expectedMark, boolean newMark):原子地将引用和标记的值设置为新值,仅在旧值与预期值相等时才进行替换。
- 参数:expectedReference - 期望的引用值,newReference - 要设置的新引用值,expectedMark - 期望的标记值,newMark - 要设置的新标记值。
- 作用:如果引用和标记的当前值与预期值相等,则将其设置为新的指定值,返回是否成功替换。
weakCompareAndSet(V expectedReference, V newReference, boolean expectedMark, boolean newMark):与compareAndSet方法类似,但使用弱比较和设置,可能因为并发操作而失败。
public class AtomicMarkableReferenceDemo {
public static void main(String[] args) {
String str1 = "字符串1";
AtomicMarkableReference<String> sasr = new AtomicMarkableReference<>(str1, true);
new Thread(() -> {
boolean marked = sasr.isMarked();
System.out.println("线程A首次内容:" + sasr.getReference() + ",标记:" + marked);
try {
Thread.sleep(500);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
sasr.compareAndSet(str1, "字符串2", marked, !marked);
System.out.println("线程A第二次内容:" + sasr.getReference() + ",标记:" + sasr.isMarked());
}).start();
new Thread(() -> {
boolean marked = sasr.isMarked();
System.out.println("线程B首次内容:" + sasr.getReference() + ",标记:" + marked);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(sasr.compareAndSet(str1, "字符串2", marked, !marked));
System.out.println("查看当前内容:" + sasr.getReference() + ",标记:" + sasr.isMarked());
}).start();
}
}
14.4对象属性原子类
14.4.1基本类型
AtomicIntegerFieldUpdater:基于反射的实用程序,可以对指定类的指定volatile int字段进行原子更新。AtomicLongFieldUpdater:基于反射的实用程序,可以对指定类的指定volatile long字段进行原子更新。AtomicReferenceFieldUpdater:基于反射的实用程序,可以对指定类的指定volatile 引用类型字段进行原子更新。
14.4.2使用目的
以线程安全的方式操作非线程安全对象内的字段。在对象的字段级别进行原子操作。
14.4.3使用要求
- 更新的对象属性必须使用
public volatile修饰符- 因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法
newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。
14.4.4AtomicIntegerFieldUpdater
AtomicIntegerFieldUpdater:基于反射的实用程序,可以对指定类的指定volatile int字段进行原子更新。
以线程安全的方式操作非线程安全对象内的字段。
对于以下案例,可以添加synchronized锁来解决。但是不要使用synchronized来实现,使用AtomicIntegerFieldUpdater来实现。
class Account{
private String name = "张三";
private int money = 0;
public void addMoney(){
money++;
}
@Override
public String toString() {
return "Account{" +
"name='" + name + '\'' +
", money=" + money +
'}';
}
}
public class AtomicFieldDemo {
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(10);
Account account = new Account();
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 1000; j++) {
new Thread(()->{
account.addMoney();
}).start();
}
countDownLatch.countDown();
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(account.toString());
}
}
使用AtomicIntegerFieldUpdater来实现。
class Account{
private String name = "张三";
private volatile int money = 0;
// 创建原子整型字段更新器
AtomicIntegerFieldUpdater<Account> atomicIntegerFieldUpdater =
AtomicIntegerFieldUpdater.newUpdater(Account.class,"money");
public void addMoney(Account account){
atomicIntegerFieldUpdater.getAndIncrement(account);
}
@Override
public String toString() {
return "Account{" +
"name='" + name + '\'' +
", money=" + money +
'}';
}
}
public class AtomicFieldDemo {
public static void main(String[] args) {
Account account = new Account();
CountDownLatch countDownLatch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) {
try {
for (int j = 0; j < 1000; j++) {
new Thread(()->{
account.addMoney(account);
}).start();
}
} finally {
countDownLatch.countDown();
}
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(account.toString());
}
}
14.4.5AtomicReferenceFieldUpdater
AtomicReferenceFieldUpdater:基于反射的实用程序,可以对指定类的指定volatile 引用类型字段进行原子更新。
class FlagDemo{
private volatile Boolean flag = Boolean.FALSE;
AtomicReferenceFieldUpdater<FlagDemo,Boolean> atomicReferenceFieldUpdater =
AtomicReferenceFieldUpdater.newUpdater(FlagDemo.class,Boolean.class,"flag");
public void method(FlagDemo flagDemo){
if(atomicReferenceFieldUpdater.compareAndSet(flagDemo,Boolean.FALSE,Boolean.TRUE)){
System.out.println(Thread.currentThread().getName() + ":正在修改");
System.out.println(Thread.currentThread().getName() + ":修改成功");
}else{
System.out.println(Thread.currentThread().getName() + ":其他线程正在修改");
}
}
}
public class AtomicReferenceFieldUpdaterDemo {
public static void main(String[] args) {
FlagDemo flagDemo = new FlagDemo();
for (int i = 1; i <= 5; i++) {
new Thread(() -> {
flagDemo.method(flagDemo);
},"线程" + i).start();
}
}
}

14.5.原子操作增强类
14.5.1原子操作增强类类型
DoubleAccumulator:一个或多个变量,它们一起保持运行double使用所提供的功能更新值DoubleAdder:一个或多个变量一起保持初始为零double总和LongAccumulator:一个或多个变量,一起保持使用提供的功能更新运行的值long ,提供了自定义的函数操作LongAdder:一个或多个变量一起维持初始为零long总和(重点),只能用来计算加法,且从0开始计算
说明:
以LongAdder为例:当多个线程更新用于收集统计信息但不用于细粒度同步控制的目的的公共和时,此类通常优于AtomicLong。在低更新争用下,这两个类具有相似的特征。但在高争用的情况下,LongAdder的预期吞
吐量明显更高,但代价是空间消耗更高。
LongAdder常用API:
void add(long x):将当前的value加x。void increment():将当前的value加1。void decrement():将当前的value减1。long sum():返回当前值。特别注息,在没有并发更新value的情况下,sum会返回一个精确值,在存在并发的情况下,sum不保证返回精确值。void reset():将value重置为0,可用于替代重新new- -个LongAdder, 但此方法只可以在没有并发更新的情况下使用。long sumThenReset():获取当前value,并将value重置为0。
LongAccumulator 类中常用的 API 包括:
accumulate(long x):使用给定值更新。get():返回当前值。reset():重置变量以保持对标识值的更新。getThenReset():相当于get()后跟reset()。
LongAdder和LongAccumulator的区别:LongAdder只能用来计算加法,且从零开始计算。而LongAccumulator提供了自定义的函数操作,在函数内部可以自定义计算规则。
14.5.2案例
案例:
public class LongAdderDemo {
public static void main(String[] args) {
LongAdder longAdder = new LongAdder();
longAdder.increment();
longAdder.increment();
longAdder.increment();
System.out.println("longAddre计算结果:"+longAdder.sum());
LongAccumulator longAccumulator =
new LongAccumulator((left, right) -> {
return left + right;
}, 0);
longAccumulator.accumulate(10);
longAccumulator.accumulate(20);
System.out.println("longAccumulator计算结果:" + longAccumulator.get());
}
}
14.6sync+atomic+longAdder+longAccumuator对比
题目要求,创建100个线程,每个线程计算100W次,总数为1亿,查看sync+atomic+longAdder+longAccumuator的计算耗时。
class Click {
private int number;
public int getNumber() {
return number;
}
public void setNumber(int number) {
this.number = number;
}
public synchronized void syncAdd() {
number++;
}
AtomicLong atomicLong = new AtomicLong(0);
public void atomicAdd() {
atomicLong.getAndIncrement();
}
LongAdder longAdder = new LongAdder();
public void longAdderAdd() {
longAdder.increment();
}
LongAccumulator longAccumulator = new LongAccumulator((left, right) -> {
return left + right;
}, 0);
public void longAccumulatorAdd() {
longAccumulator.accumulate(1);
}
}
public class ClickCountDemo {
public static final int tenThousand = 10000;
public static final int threadNumber = 100;
public static void main(String[] args) {
Click click = new Click();
long start;
long end;
CountDownLatch syncCountDownLatch = new CountDownLatch(threadNumber);
CountDownLatch atomicCountDownLatch = new CountDownLatch(threadNumber);
CountDownLatch longAdderCountDownLatch = new CountDownLatch(threadNumber);
CountDownLatch longAccumultorCountDownLatch = new CountDownLatch(threadNumber);
// 测试synchronized
start = System.currentTimeMillis();
for (int i = 0; i < threadNumber; i++) {
new Thread(() -> {
try {
for (int j = 0; j < tenThousand * 100; j++) {
click.syncAdd();
}
} finally {
syncCountDownLatch.countDown();
}
}).start();
}
try {
syncCountDownLatch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
end = System.currentTimeMillis();
long syncTime = end - start;
System.out.println("synchronized锁花费的时间为:" + syncTime + "ms,计算结果为:" + click.getNumber());
// 测试atomicLong
start = System.currentTimeMillis();
for (int i = 0; i < threadNumber; i++) {
new Thread(() -> {
for (int j = 0; j < tenThousand * 100; j++) {
try {
click.atomicAdd();
} finally {
atomicCountDownLatch.countDown();
}
}
}).start();
}
try {
atomicCountDownLatch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
end = System.currentTimeMillis();
long atomicTime = end - start;
System.out.println("atomicLong花费的时间为:" + atomicTime + "ms,计算结果为:" + click.getNumber());
// 测试LongAdder
start = System.currentTimeMillis();
for (int i = 0; i < threadNumber; i++) {
new Thread(() -> {
try {
for (int j = 0; j < tenThousand * 100; j++) {
click.longAdderAdd();
}
} finally {
longAdderCountDownLatch.countDown();
}
}).start();
}
try {
longAdderCountDownLatch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
end = System.currentTimeMillis();
long longAdderTime = end - start;
System.out.println("longAdder花费的时间为:" + longAdderTime + "ms,计算结果为:" + click.getNumber());
// 测试longAccumulator
start = System.currentTimeMillis();
for (int i = 0; i < threadNumber; i++) {
new Thread(() -> {
try {
for (int j = 0; j < tenThousand * 100; j++) {
click.longAccumulatorAdd();
}
} finally {
longAccumultorCountDownLatch.countDown();
}
}).start();
}
try {
longAdderCountDownLatch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
end = System.currentTimeMillis();
long longAccumulatorTime = end - start;
System.out.println("longAccumulator花费的时间为:" + longAccumulatorTime + "ms,计算结果为:" + click.getNumber());
}
}从结果可以看出:
- LongAdder适合的场景是统计求和计数的场景
- 在高并发的情况下,LongAdder的效率比AtomicLong高,但要消耗更多的空间
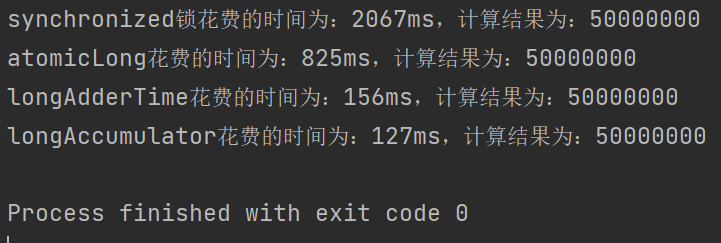
14.7LongAdder解析
14.7.1LongAdder的继承关系
Striped64类当中一些变量的定义:
static final int *NCPU* = Runtime.*getRuntime*().availableProcessors();CPU 数,以限制表大小
transient volatile Cell[] cells;单元格表。当为非空时,大小为 2 的幂。
transient volatile long base;基值,主要用于没有争用的情况,但也用作表初始化争用期间的回退。通过 CAS 更新。
transient volatile int cellsBusy;旋转锁(通过 CAS 锁定)在调整大小和/或创建单元格时使用。
14.7.2LongAdder的效率分析
LongAdder 在高并发场景下能够提供优异的性能,主要是因为它采用了一种称为“分散累加”(scatter/gather)的策略,通过将加法操作分散到多个独立的变量(Cell)上,避免了竞争条件。
LongAdder 内部维护了一个 Cell 数组,每个 Cell 都包含一个值,并提供对这个值的 CAS 操作。当多个线程同时进行加法操作时,LongAdder 会将这些加法操作分摊到不同的 Cell 上,从而减少竞争条件的出现。此外,LongAdder 还维护了一个名为 base 的变量,用于存储没有被分配到 Cell 的加法操作的结果。
当需要获取最终的加法结果时,LongAdder 会将 base 和所有 Cell 中的值进行求和,得到最终的结果。这种设计使得 LongAdder 在高并发环境下能够提供优异的性能。
相比之下,如果使用传统的锁或原子变量来实现线程安全的加法操作,则在高并发场景下会出现大量竞争,导致性能下降。而 LongAdder 通过将竞争分散到多个变量上,有效地避免了这个问题。
即:
- 内部有一个base变量,一个Cell[]数组
- base变量:低并发,直接累加到该变量上
- Cell[]数组:高并发,累加进各个线程自己的槽Cell[i]中
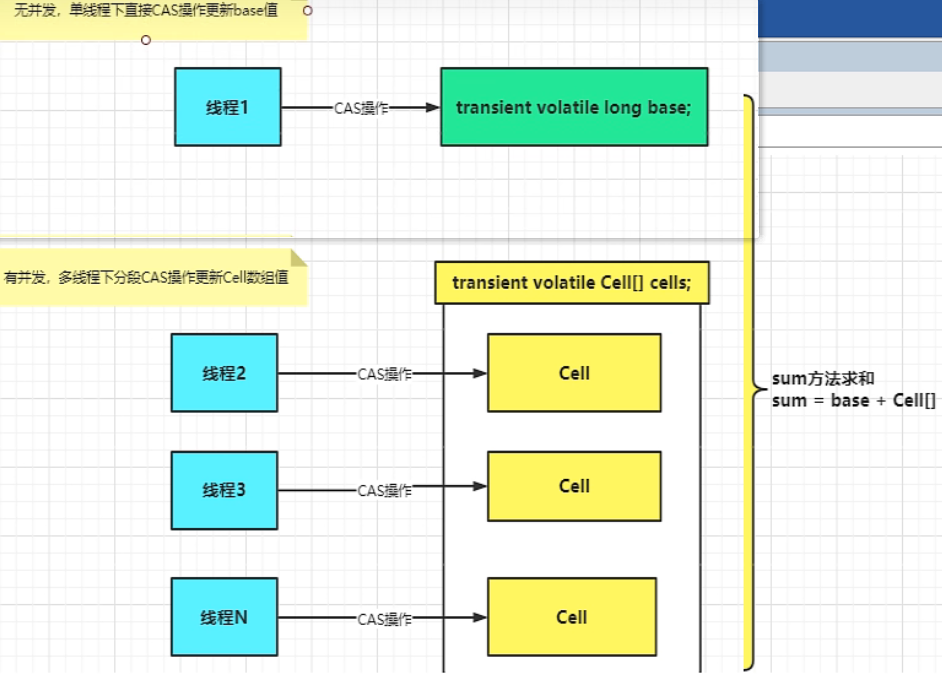

14.7.3LongAdder源码分析
LongAdder在无竞争的情况下,跟AtomicLong一样,对同一个base进行操作,当出现竞争关系时则是采用分散累加做法,用空间换时间,用一个数组cells,将一个value值拆分进这个数组cells。多个线程需要同时对value进行操作的时候,可以对线程id进行hash得到hash值,再根据hash值映射到这个数组cells的某个下标,再对该下标所对应的值进行自增操作。当所有线程操作完毕,将数组cells的所有值和base都加起来作为最终结果。

查看LongAdder的increment方法。
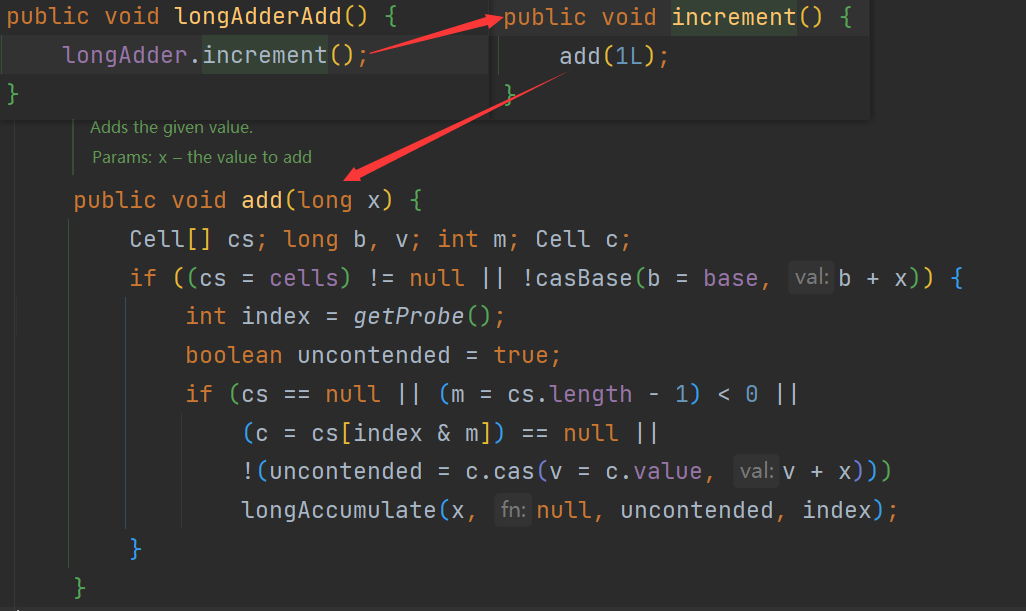
//将给定值相加。
//参数:
//x – 要增加的价值
public void add(long x) {
//cs表示cells引用
//b表示获取的base值
//v表示期望值
//m表示cells数组的长度
//c表示当前线程命名中的cell单元格
Cell[] cs; long b, v; int m; Cell c;
if ((cs = cells) != null || !casBase(b = base, b + x)) {
int index = getProbe();
boolean uncontended = true;
if (cs == null || (m = cs.length - 1) < 0 ||
(c = cs[index & m]) == null ||
!(uncontended = c.cas(v = c.value, v + x)))
longAccumulate(x, null, uncontended, index);
}
}
- 如果Cells表为空,尝试用CAS更新base字段,成功则退出
- 如果Cells表为空,CAS更新base字段失败,出现竞争,uncontended为true,调用longAccumulate(新建数组)
- 如果Cells表非空,但当前线程映射的槽为空,uncontended为true,调用longAccumulate(初始化)
- 如果Cells表非空,且当前线程映射的槽非空,CAS更新Cell的值,成功则返回,否则,uncontended设为false,调用longAccumulate(扩容)
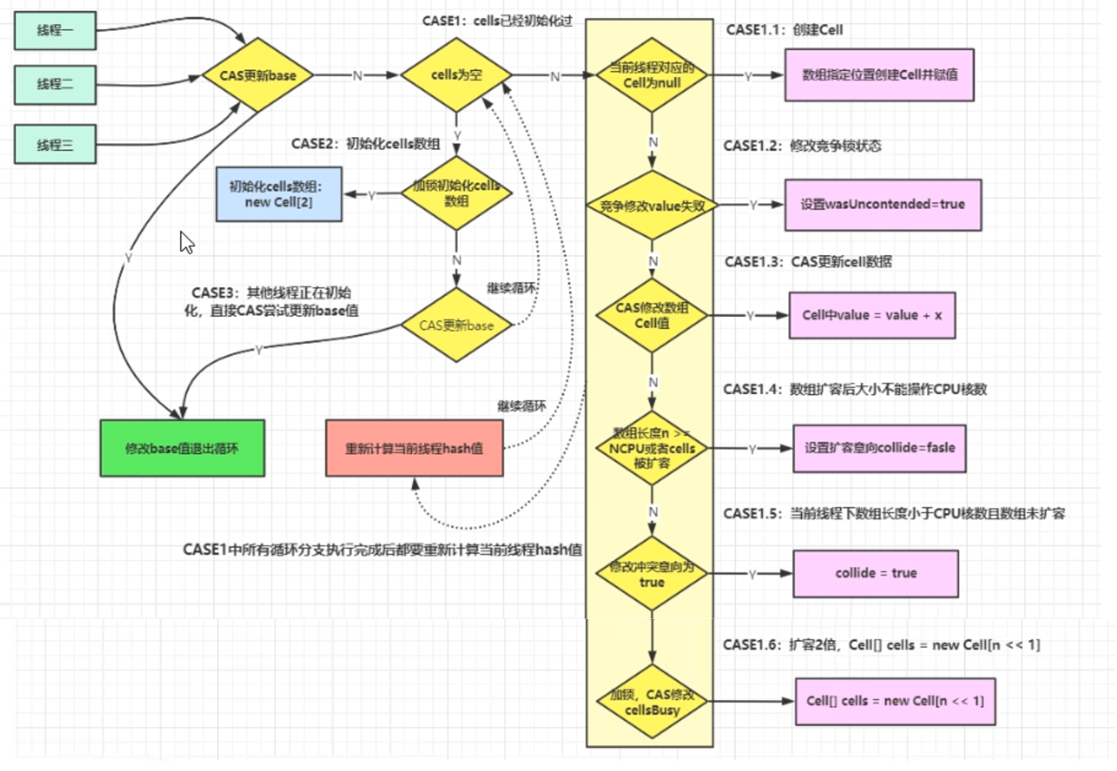
14.7.4LongAdder和AtomicLong总结
AtomicLong
- 原理:CAS+自旋
- 场景:低并发下的全局计算,AtomicLong能保证并发情况下计数的准确性,其内部通过CAS来解决并发安全性问题
- 优点:AtomicLong线程安全,可允许一些性能损耗,要求高精度时可使用,保证精度,多个线程对单个热点值value进行了原子操作——保证精度,性能代码
- 缺陷:高并发后性能急剧下降——AtomicLong的自旋会成为瓶颈(N个线程CAS操作修改线程的值,每次只有一个成功过,其他N-1失败,失败的不停自旋直至成功,这样大量自旋会降低程序性能)
LongAdder
- 原理:CAS+Base+Cell数组分散-分散累加
- 场景:高并发下的全局计算
- 优点:LongAdder当需要在高并发场景下有较好的性能表现,且对值得精确度要求不高时,可以使用,LongAdder时每个线程拥有自己得槽,各个线程一般只对自己槽中得那个值进行CAS操作——保证性能,精度代价
- 缺陷:sum求和后还有计算线程修改结果的话,最后结果不够准确
15.ThreadLocal
15.1ThreadLocal简介
ThreadLocal叫做线程局部变量,意思是ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的,也就是说该变量是当前线程独有的变量。ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。
ThreadLoal 线程局部变量,同一个ThreadLocal所包含的对象,在不同的 Thread 中有不同的副本。即:每个 Thread 有自己的实例副本,且其它 Thread 不可访问,那就不存在多线程间共享的问题。
总的来说,ThreadLocal 适用于每个线程需要自己独立的实例且该实例需要在多个方法中被使用,也即变量在线程间隔离而在方法或类间共享的场景。
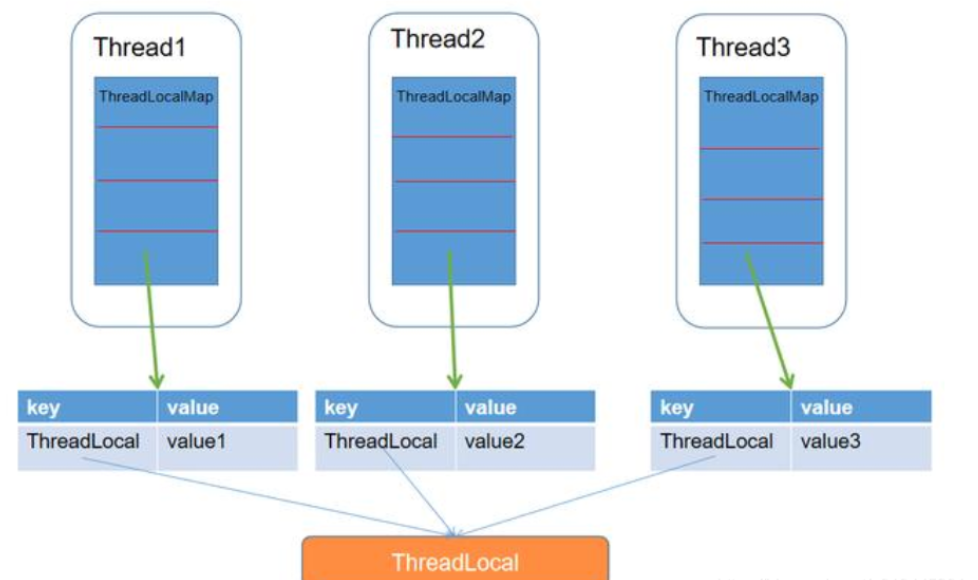
15.2ThreadLocal和Synchronized的区别
ThreadLocal和Synchonized都用于解决多线程并发访问。
但是ThreadLocal与synchronized有本质的区别:
Synchronized用于线程间的数据共享,而ThreadLocal则用于线程间的数据隔离。
Synchronized是利用锁的机制,使变量或代码块在某一时该只能被一个线程访问。而ThreadLocal为每一个线程都提供了变量的副本,使得每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享,而Synchronized却正好相反,它用于在多个线程间通信时能够获得数据共享。
15.3ThreadLocal的API
| 修饰符和类型 | 方法和说明 |
|---|---|
T |
get():返回此线程局部变量在当前线程此的副本中的值。 |
protected T |
initialValue():返回此线程局部变量当前线程的“初始值”。 |
void |
remove():删除此线程局部变量在当前线程的值。 |
void |
set(T value):将此线程局部变量在当前线程的副本设置为指定值。 |
static <S> ThreadLocal<S> |
withInitial(Supplier<? extends S> supplier):创建一个线程局部变量。 |
案例:
class Saler {
// 创建一个ThreadLocal对象,用于存放每个线程的数据
ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
public void addNumberThreadLocal() {
threadLocal.set(threadLocal.get() + 1);
}
}
/**
* 销售演示
*
* @author Xu huaiang
* @date 2023/07/06
*/
public class SaleDemo {
public static void main(String[] args) {
Saler saler = new Saler();
CountDownLatch countDownLatch = new CountDownLatch(5);
for (int i = 1; i <= 5; i++) {
new Thread(() -> {
int number = new Random().nextInt(5) + 1;
// 每位销售卖出的商品数量
for (int j = 1; j <= number; j++) {
saler.addNumberThreadLocal();
}
System.out.println(Thread.currentThread().getName() + "号销售" + "卖出了" + number + "件商品");
countDownLatch.countDown();
}, String.valueOf(i)).start();
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
15.4ThrealLocal变量回收
阿里巴巴java开发手册中规定:必须回收自定义的Threadlocal 变量, 尤其在线程池场景下,线程经常会被复用, 如果不清理自定义的Threadlocal变量,可能会影响后续业务逻辑和造成内存泄露等问题。尽量在代理中使用try-finally块进行回收。
案例:
class ThrealLocalData {
ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
public void addNumberThreadLocal() {
threadLocal.set(threadLocal.get() + 1);
}
}
public class VariableRecovery {
public static void main(String[] args) {
// 创建一个ThreadLocal对象,用于存放每个线程的数据
ThrealLocalData threalLocalData = new ThrealLocalData();
// 获取到线程池
ThreadPoolExecutor threadPool = ThreadPoolService.getThreadPool();
try {
for (int i = 0; i < 20; i++) {
threadPool.execute(() -> {
Integer before = threalLocalData.threadLocal.get();
System.out.println(Thread.currentThread().getName() + "号线程执行前的值:" + before);
threalLocalData.addNumberThreadLocal();
threalLocalData.threadLocal.get();
System.out.println(Thread.currentThread().getName() + "号线程执行后的值:" + threalLocalData.threadLocal.get());
});
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}查看结果:出现线程复用
使用remove()函数删除此线程局部变量在当前线程当中的值。即使线程复用也不会出现重复值。
class ThrealLocalData {
ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
public void addNumberThreadLocal() {
threadLocal.set(threadLocal.get() + 1);
}
}
public class VariableRecovery {
public static void main(String[] args) {
// 创建一个ThreadLocal对象,用于存放每个线程的数据
ThrealLocalData threalLocalData = new ThrealLocalData();
// 获取到线程池
ThreadPoolExecutor threadPool = ThreadPoolService.getThreadPool();
try {
for (int i = 0; i < 20; i++) {
threadPool.execute(() -> {
try {
Integer before = threalLocalData.threadLocal.get();
System.out.println(Thread.currentThread().getName() + "号线程执行前的值:" + before);
threalLocalData.addNumberThreadLocal();
threalLocalData.threadLocal.get();
System.out.println(Thread.currentThread().getName() + "号线程执行后的值:" + threalLocalData.threadLocal.get());
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threalLocalData.threadLocal.remove();
}
});
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
threadPool.shutdown();
}
}
}
15.5ThreadLocal源码分析
查看Thread类:
可以看到Thread 类中包含一个名为 threadLocals 的字段,它是一个 ThreadLocal.ThreadLocalMap 类型的对象。这个字段用于存储与当前线程相关联的 ThreadLocal 变量。每个 ThreadLocal 对象都会在 threadLocals 中维护一个与当前线程相关联的变量副本。这样,每个线程都可以通过 ThreadLocal 对象访问自己的变量副本,而不会影响其他线程的变量副本。

查看ThreadLcoal类当中,发现ThreadLocalMap为ThreadLocal类的静态内部类。
而ThreadLocalMap 中的键值对存储在一个名为 Entry 的内部类中。Entry 类继承自 WeakReference 类,因此它对键的引用是弱引用。这意味着,如果一个 ThreadLocal 对象不再被使用,那么它所对应的键值对就会在下一次垃圾回收时被回收。
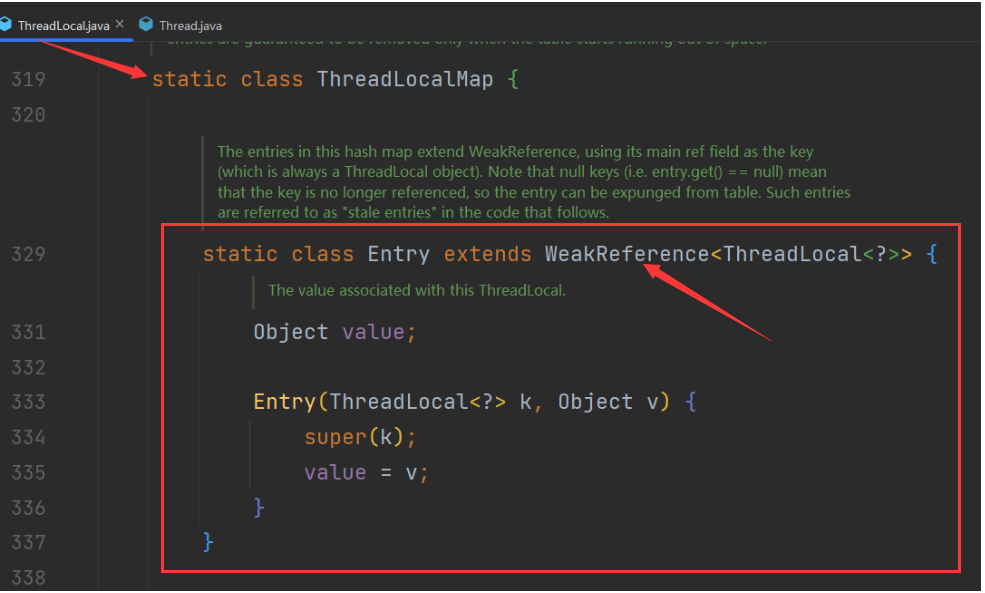
Thread是 Java 中表示线程的类。ThreadLocal是一个类,它提供了线程局部变量。这些变量与它们的普通副本不同,因为每个访问它的线程(通过其 get 或 set 方法)都有自己独立初始化的变量副本。ThreadLocalMap是ThreadLocal的一个静态内部类,它是一个定制的哈希映射,仅用于维护线程局部值。ThreadLocalMap实际上就是一个以ThreadLocal实例为Key,任意对象为value的Entry对象(弱引用对象),当我们为ThreadLocal变量赋值,实际上就是以当前ThreadLocal实例为Key,值为value的Entry往这个ThreadLocalMap中存放。
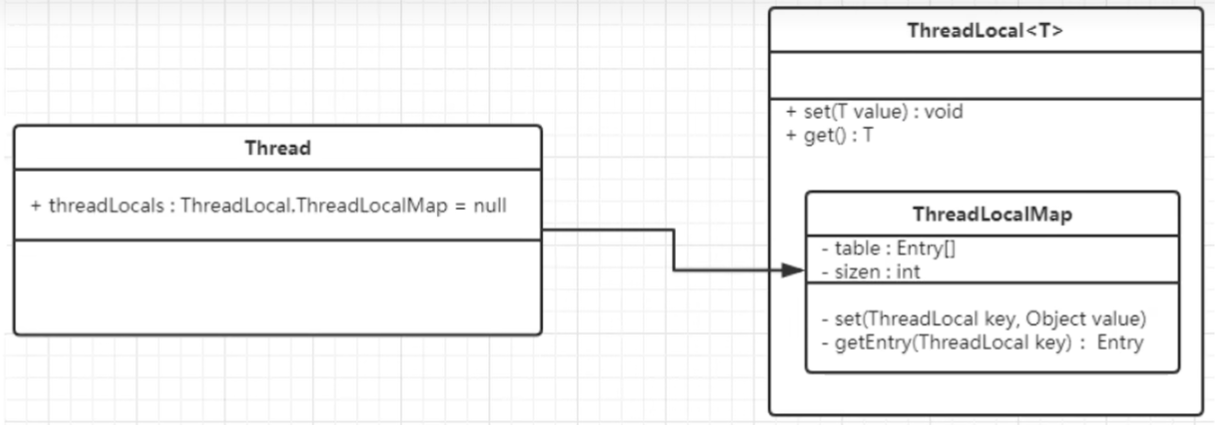
每个 Thread 对象都有一个 ThreadLocalMap 属性,用于存储与该线程关联的线程局部变量。当您调用 ThreadLocal 的 set 或 get 方法时,实际上是在操作当前线程的 ThreadLocalMap。所以ThreadLocalMap 是一个中间媒介,它将 ThreadLocal 变量与特定的 Thread 关联起来。
即ThreadLocal本身并不存储值,它只是作为一个key来让线程从ThreadLocalMap中获取value。真正的存储结构是ThreadLocal中的内部类ThreadLocalMap,每个Thread对象维护着一个ThreadLocalMap的引用,用Entry来进行存储。
- 调用ThreadLocal的
set()方法时, 实际上就是往ThreadLocalMap设置值, key是ThreadLocal对象,值Value是传递进来的对象。- 调用ThreadLocal的
get()方法时, 实际上就是往ThreadLocalMap获取值,key是ThreadLocal对象。
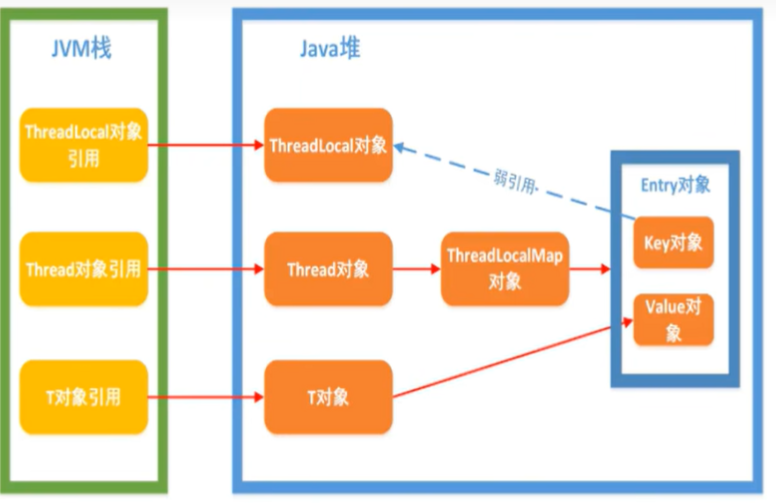
15.6ThreadLocal的内存泄露问题
15.6.1什么是内存泄露
内存泄漏:就是将对一个不再被引用的对象进行GC的时候,发现其还存在对象的引用,从而导致的该对象不能回收仍然占用内存的问题,这就是内存泄漏。
15.6.2引用的分类
我们希望能描述这样一类对象:当内存空间还足够时,则能保留在内存中;如果内存空间在进行垃圾收集后还是很紧张,则可以抛弃这些对象。
【既偏门又非常高频的面试题】强引用、软引用、弱引用、虚引用有什么区别?具体使用场景是什么?
在JDK1.2版之后,Java对引用的概念进行了扩充,将引用分为:强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Reference)、虚引用(Phantom Reference)这4种引用强度依次逐渐减弱。
除强引用外,其他3种引用均可以在java.lang.ref包中找到它们的身影。如下图,显示了这3种引用类型对应的类,开发人员可以在应用程序中直接使用它们。

Reference子类中只有终结器引用是包内可见的,其他3种引用类型均为public,可以在应用程序中直接使用
强引用(StrongReference):最传统的“引用”的定义,是指在程序代码之中普遍存在的引用赋值,即类似“
Object obj = new Object()”这种引用关系。只有当它不再被引用时,垃圾回收器才会回收它所指向的对象。软引用(SoftReference):垃圾回收器会在内存不足时回收它所指向的对象,即使这个对象仍然被引用。
弱引用(WeakReference):当进行垃圾回收时,无论内存空间是否足够,都会回收掉被弱引用关联的对象。
虚引用(PhantomReference):它不会影响垃圾回收器对它所指向的对象的回收。虚引用主要用于跟踪对象被垃圾回收器回收的时间。
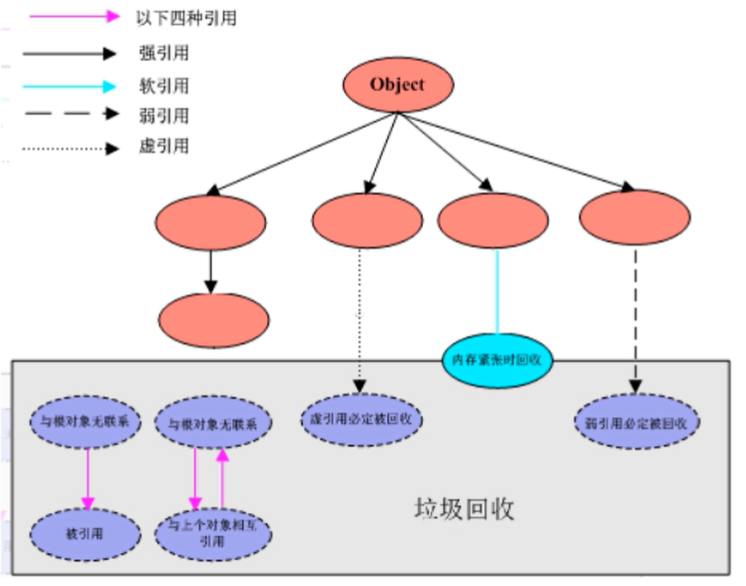
15.6.3强引用(Strong Reference)—不回收
在Java程序中,最常见的引用类型是强引用(普通系统99%以上都是强引用),也就是我们最常见的普通对象引用,也是默认的引用类型。
当在Java语言中使用new操作符创建一个新的对象,并将其赋值给一个变量的时候,这个变量就成为指向该对象的一个强引用。
强引用所指向的对象在任何时候都不会被系统回收,当然是对于还被引用的对象。对于一个普通的对象,如果没有其他的引用关系,只要超过了引用的作用域或者显式地将相应(强)引用赋值为nu11,就是可以当做垃圾被收集了,当然具体回收时机还是要看垃圾收集策略。
相对的,软引用、弱引用和虚引用的对象是软可触及、弱可触及和虚可触及的,在一定条件下,都是可以被回收的。所以,强引用是造成Java内存泄漏的主要原因之一。
强引用例子
StringBuffer str = new StringBuffer("hello mogublog");局部变量str指向StringBuffer实例所在堆空间,通过str可以操作该实例,那么str就是StringBuffer实例的强引用
对应内存结构
此时,如果再运行一个赋值语句
StringBuffer str1 = str;对应的内存结构
本例中的两个引用,都是强引用,强引用具备以下特点:
强引用可以直接访问目标对象。
强引用所指向的对象在任何时候都不会被系统回收,虚拟机宁愿抛出OOM异常,也不会回收强引用所指向对象(在还在被引用的前提下)。
强引用可能导致内存泄漏。
15.6.4软引用(Soft Reference)—内存不足即回收
软引用是用来描述一些还有用,但非必需的对象。只被软引用关联着的对象,在系统将要发生内存溢出异常前,会把这些对象列进回收范围之中进行第二次回收,如果这次回收还没有足够的内存,才会抛出内存溢出异常。
软引用通常用来实现内存敏感的缓存。比如:高速缓存就有用到软引用。如果还有空闲内存,就可以暂时保留缓存,当内存不足时清理掉,这样就保证了使用缓存的同时,不会耗尽内存。
垃圾回收器在某个时刻决定回收软可达的对象的时候,会清理软引用,并可选地把引用存放到一个引用队列(Reference Queue)。
类似弱引用,只不过Java虚拟机会尽量让软引用的存活时间长一些,迫不得已才清理。
在JDK1.2版之后提供了java.lang.ref.SoftReference类来实现软引用
Object obj = new Object(); // 声明强引用
SoftReference<Object> sf = new SoftReference<>(obj);
obj = null; //销毁强引用15.6.5弱引用(Weak Reference)—GC即回收
弱引用也是用来描述那些非必需对象,只被弱引用关联的对象只能生存到下一次垃圾收集发生为止。在系统GC时,只要发现弱引用,不管系统堆空间使用是否充足,都会回收掉只被弱引用关联的对象。
但是,由于垃圾回收器的线程通常优先级很低,因此,并不一定能很快地发现持有弱引用的对象。在这种情况下,弱引用对象可以存在较长的时间。
弱引用和软引用一样,在构造弱引用时,也可以指定一个引用队列,当弱引用对象被回收时,就会加入指定的引用队列,通过这个队列可以跟踪对象的回收情况。
软引用、弱引用都非常适合来保存那些可有可无的缓存数据。如果这么做,当系统内存不足时,这些缓存数据会被回收,不会导致内存溢出。而当内存资源充足时,这些缓存数据又可以存在相当长的时间,从而提升系统性能。
在JDK1.2版之后提供了WeakReference类来实现弱引用
Object obj = new Object(); // 声明强引用
WeakReference<Object> sf = new WeakReference<>(obj);
obj = null; //销毁强引用弱引用对象与软引用对象的最大不同就在于,当GC在进行回收时,需要通过算法检查是否回收软引用对象,而对于弱引用对象,GC总是进行回收。弱引用对象更容易、更快被GC回收。
面试题:你开发中使用过WeakHashMap吗?
WeakHashMap用来存储图片信息,可以在内存不足的时候,及时回收,避免了OOM
15.6.6虚引用(Phantom Reference)—对象回收跟踪
也称为“幽灵引用”或者“幻影引用”,是所有引用类型中最弱的一个。
一个对象是否有虚引用的存在,完全不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它和没有引用几乎是一样的,随时都可能被垃圾回收器回收。
它不能单独使用,也无法通过虚引用来获取被引用的对象。当试图通过虚引用的get()方法取得对象时,总是null。
为一个对象设置虚引用关联的唯一目的在于跟踪垃圾回收过程。比如:能在这个对象被收集器回收时收到一个系统通知。
虚引用必须和引用队列一起使用。虚引用在创建时必须提供一个引用队列作为参数。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象后,将这个虚引用加入引用队列,以通知应用程序对象的回收情况。
由于虚引用可以跟踪对象的回收时间,因此,也可以将一些资源释放操作放置在虚引用中执行和记录。
在JDK1.2版之后提供了PhantomReference类来实现虚引用。
Object obj = new Object(); // 声明强引用
ReferenceQueue phantomQueue = new ReferenceQueue();
PhantomReference<Object> sf = new PhantomReference<>(obj, phantomQueue);
obj = null;15.6.7ThreadLocal内存泄漏
ThreadLocalMap是ThreadLocal的内部类,它用于存储每个线程的变量副本。ThreadLocalMap的键是ThreadLocal实例,而值是线程的变量副本。由于ThreadLocalMap的生命周期与Thread一样长,如果没有手动删除对应的键,那么就会导致内存泄漏。而在ThreadLocalMap中,键是弱引用,而值是强引用。那么在进行垃圾回收时,键必然会被回收,但值不会被回收。这样就会导致内存泄漏。
为了避免这种情况,可以在不再使用 ThreadLocal 对象时调用它的 remove() 方法来清除对应的值。这样可以确保不会发生内存泄漏。(也就是在15.4章节说明的ThreadLocal变量回收)。
15.6.8ThreadLocalMap为什么使用弱引用
ThreadLocalMap 使用弱引用来引用键(ThreadLocal 对象),这样可以避免内存泄漏。
在 ThreadLocalMap 中,每个 ThreadLocal 对象都对应一个键值对,其中键是 ThreadLocal 对象,值是与当前线程相关联的变量副本。如果 ThreadLocalMap 使用强引用来引用键,那么即使 ThreadLocal 对象不再被使用而被其他对象引用,它所对应的键仍然会存在于 ThreadLocalMap 中。那么它所对应的值也不会被垃圾回收器回收,从而导致内存泄漏。
为了避免这种情况,ThreadLocalMap 使用弱引用来引用键。这样,在垃圾回收时,无论 ThreadLocal 对象是否仍然被使用,它所对应的键都会被回收。这样可以确保不会发生内存泄漏。而ThreadLocalMap中对应的Entry的key会变为null 。
15.6.9ThreadLocalMap使用弱引用存在的问题
当ThreadLocalMap中对应的Entry的key变为null时,仍然存在内存泄漏的问题。这是因为Entry中的value仍然被引用,而且不会被垃圾回收器回收。为了避免这个问题,ThreadLocalMap的实现会定期检查并清理key为null的Entry。此外,在使用ThreadLocal时,也应该注意在不再使用时及时调用remove方法来删除对应的value。
16.对象的内存布局
**对象在堆空间的内存布局有以下三部分组成**:
- 对象头
- 实例数据
- 对齐填充
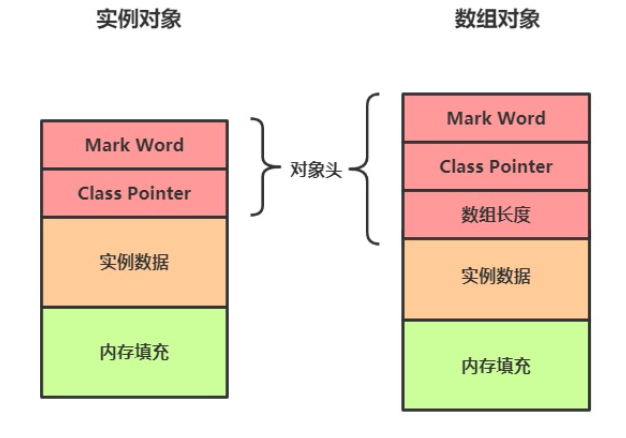
16.1 对象头(Header)
对象头包含了两部分,分别是对象标记(Mark Word)和类型指针(Class Pointer)。如果是数组,还需要记录数组的长度。
对象头(Object Header)的大小取决于JVM的架构和对象本身。在32位的JVM中,对象头的大小至少为8字节,包括4字节的对象标记(Mark Word)和4字节的类型指针(Klass Word)。而在64位的JVM中,对象头的大小至少为12字节或16字节,具体取决于是否开启了指针压缩(CompressedOops)。如果开启了指针压缩,对象头的大小为12字节,包括8字节的对象标记和4字节的类型指针;如果没有开启指针压缩,对象头的大小为16字节,包括8字节的对象标记和8字节的类型指针。
此外,如果对象是一个数组,那么对象头还需要额外的4个或8个字节来存储数组长度(Array Length),具体取决于JVM的架构和是否开启了指针压缩。
16.1.1对象标记(Mark Word)
对象标记(Mark Word)的大小也取决于JVM的架构。在32位的JVM中,对象标记的大小为32位,也就是4字节。而在64位的JVM中,对象标记的大小为64位,也就是8字节。
- 哈希值(HashCode):用于确定对象在哈希表中的位置。可以通过调用对象的
hashCode()方法来获取对象的哈希值。如果没有调用hashCode方法,那么就不在对象头中的对象标记中记录哈希值。- GC分代年龄:用于确定对象是否需要在垃圾回收时晋升到老年代。
- 线程持有的锁:用于确定哪个线程持有了对象的锁。
- 锁状态标志:用于确定对象的锁状态,例如无锁、偏向锁、轻量级锁或重量级锁。
- 偏向线程ID:用于确定哪个线程持有了对象的偏向锁。
- 偏向时间戳:用于记录偏向锁的获取时间。

16.1.2类型指针
类型指针就是一个指向方法区当中该类元数据信息的指针。这样,虚拟机就能够通过这个指针快速地访问到该类的元数据信息,从而实现对对象的操作。
例如,当我们调用一个对象的方法时,虚拟机会根据对象头中的类型指针找到方法区中存储的该类的方法信息,然后根据方法信息中的指令执行相应的操作。
类型指针(Klass Word)的大小取决于JVM的架构。在32位的JVM中,类型指针的大小为32位,也就是4字节。而在64位的JVM中,类型指针的大小为64位,也就是8字节。不过,在64位的JVM中,可以通过开启指针压缩(CompressedOops)来减小类型指针的大小,将其压缩至32位(4字节)。
可以通过添加JVM参数来显式配置指针压缩。
-XX:+UseCompressedOops // 开启指针压缩
-XX:-UseCompressedOops // 关闭指针压缩16.1.3数组长度
只有数组对象才有。数组长度(Array Length)的大小也取决于JVM的架构。在32位的JVM中,数组长度的大小为32位,也就是4字节。而在64位的JVM中,数组长度的大小为64位,也就是8字节。不过,在64位的JVM中,可以通过开启指针压缩(CompressedOops)来减小数组长度的大小,将其压缩至32位(4字节)。
16.2实例数据(Instance Data)
实例数据中存储了对象的有效信息,包括从父类继承的信息和子类中定义的信息。实例数据部分的大小取决于对象所属类中定义的字段类型和数量。
- 相同宽度的字段总是被分配在一起
- 父类中定义的变量会出现在子类之前
16.3对齐填充(Padding)
对齐填充(Padding)是对象内存布局中的另一部分。它并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。
由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,也就是对象的大小必须是8字节的整数倍。因此当对象实例数据部分没有对齐的话,就需要通过对齐填充来补全。如果对象的大小就是8字节的整数倍,那么就不用再进行对齐填充了。
16.3.1对象内存布局图示
对于以下程序:
public class Customer{
public static void main(String[] args) {
Customer cust = new Customer();
}
}对于以上代码
- 虚拟机栈当中存储的是一个个的栈帧,每一个栈帧又代表着一个个方法的调用。
- 由于main方法是静态方法,所以this并不存在于局部变量表中。局部标量表中有args和cust。
- 局部变量表中的对象引用指向了堆空间当中的对象实例。其中对象实例分为对象头和实例数据。
- 对象头当中又分为运行时元数据和类型指针,类型指针指向方法区当中的类元信息。
- 运行时元数据又分为哈希值、GC分代年龄、线程所持有的锁、锁状态、偏向线程ID以及偏向时间戳。
- 实例数据当中存在的是对象真正有用的信息。

16.3.2对象内存布局示例
16.3.2.1JOL工具介绍
JOL (Java Object Layout) 是一个分析 JVM 中对象内存布局的工具。可以查看对象的内存布局、内存踪迹和引用。这使得 JOL 的分析比其它工具更精确。通过 OpenJDK 官方提供的 JOL 工具,我们即可很方便分析、了解一个 Java 对象在内存当中的具体布局情况
使用:在Maven中引入JOL依赖
<!-- JOL依赖 -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>16.3.2.2查看对象的内存布局信息
| 字段 | 含义 |
|---|---|
| OFFSET | 偏移量,也就是到这个字段位置所占用的byte数 |
| SIZE | 该类型字节大小 |
| TYPE | Class中定义的类型 |
| DESCRIPTION | 描述 |
| VALUE | 内存中的值 |
- 只有对象头
class User{
}
public class JOLDemo {
public static void main(String[] args) {
User user = new User();
// 查看对象内部信息
System.out.println(ClassLayout.parseInstance(user).toPrintable());
}
}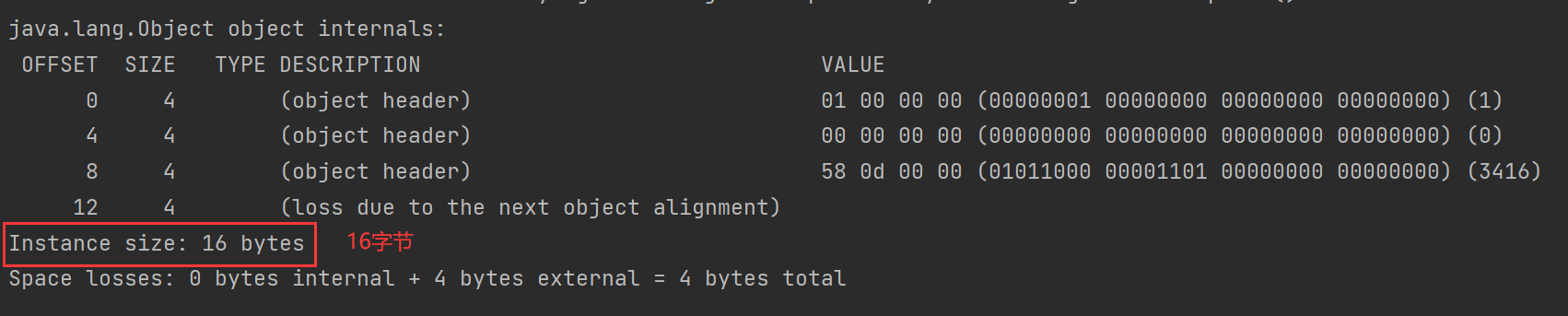
由于该对象是一个空对象。查看对象的内存布局发现只有对象头信息。因为对象头在64bit的JVM当中最少为12或者是16bit(12bit就是开启了指针压缩,将类型指针由8bit压缩到了4bit)。则0-4和4-8是就是对象标记(Mark Word),8-12就是被压缩后的类型指针。
由于JVM要求对象的起始地址要为8字节的整数倍,也就是对象大小要为8字节的整数倍。当前为12字节,所以采取对齐填充将对象大小由12字节增大到16字节。
- 对象添加字段,含有对象头+实例数据
class User{
private int age;
private boolean married;
}
public class JOLDemo {
public static void main(String[] args) {
User user = new User();
// 查看对象内部信息
System.out.println(ClassLayout.parseInstance(user).toPrintable());
}
}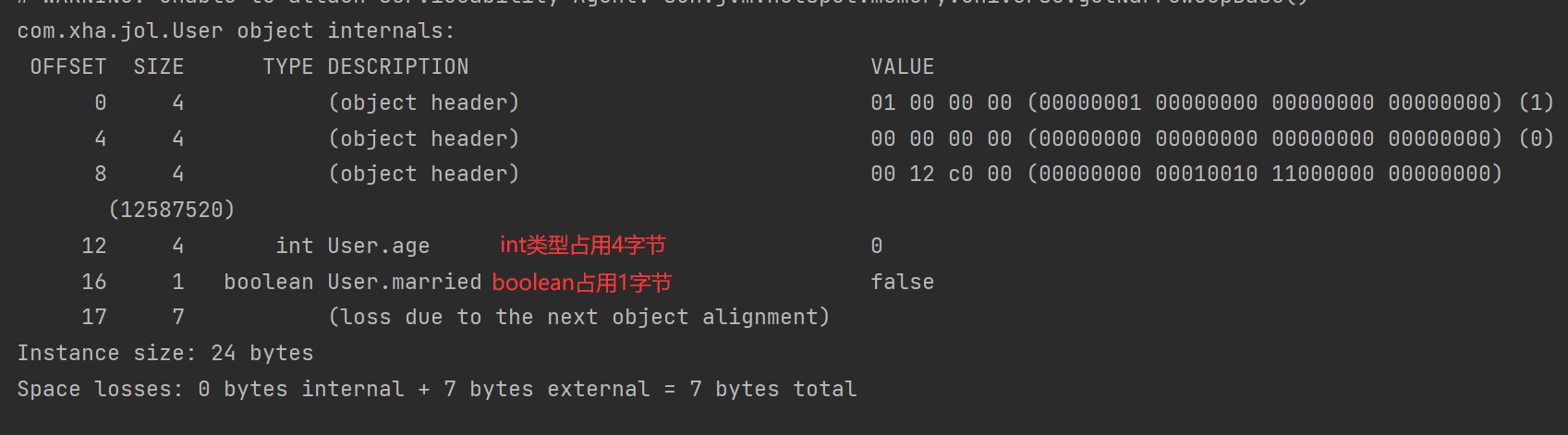
从上图可以看出,对象头占用12字节。实例数据中int类型的字段age占用4字节,boolean类型的字段married占用1字节,所用一共是17字节。
由于JVM要求对象的起始地址要为8字节的整数倍,也就是对象大小要为8字节的整数倍。当前为17字节,所以采取对齐填充将对象大小由17字节增大到24字节。
16.3.2.3分析GC分代年龄
GC分代年龄为什么是15?
因为在对象头当中的对象标识的GC分代年龄就是使用4bit来存储的。4bit表示的最大10进制数就是15(即最大1111)。
16.3.2.4压缩指针
- 查看压缩指针参数
首先使用以下命令打印出那些已经被设置过的详细的XX参数的名称和值。
java -XX:+PrintCommandLineFlags -version
- 查看压缩指针场景
class User{
}
public class JOLDemo {
public static void main(String[] args) {
User user = new User();
// 查看对象内部信息
System.out.println(ClassLayout.parseInstance(user).toPrintable());
}
}
从上图可以看出,对象头占用12字节。实例数据中int类型的字段age占用4字节,boolean类型的字段married占用1字节,所用一共是17字节。
由于JVM要求对象的起始地址要为8字节的整数倍,也就是对象大小要为8字节的整数倍。当前为17字节,所以采取对齐填充将对象大小由17字节增大到24字节。
- 关闭压缩指针
使用命令:
-XX:+UseCompressedClassPointers17.synchronized锁升级
17.1synchronized性能变化
Java5以前,只有synchronized,这个是操作系统级别的重量级操作
重量级锁,假如锁的竞争比较激烈的话,性能下降
Java 5之前 用户态和内核态之间的转换
java的线程是映射到操作系统原生线程之上的,如果要阻塞或唤醒一个线程就需要操作系统介入,需要在户态与核心态之间切换,这种切换会消耗大量的系统资源,因为用户态与内核态都有各自专用的内存空间,专用的寄存器等,用户态切换至内核态需要传递给许多变量、参数给内核,内核,也需要保护好用户态在切换时的一-些寄存器值、变量等,以便内核态调用结束后切换回用户态继续工作。
在Java早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor) 是依赖于底层的操作系统的
Mutex Lock(系统互斥量)来实现的,挂起线程和恢复线程都需要转入内核态去完成,阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态切换需要耗费处理器时间,如果同步代码块中内容过于简单,这种切换的时间可能比用户代码执行的时间还长”,时间成本相对较高,这也是为什么早期的synchronized效率低的原因Java 6之后,为了减少获得锁和释放锁所带来的性能消耗,引入了轻量级锁和偏向锁。即用来减少用户态和内核态之间的切换。

17.2为什么每一个对象都可以作为锁
在Java中,每个对象都有一个与之关联的监视器锁(monitor lock),也可以称作内置锁(intrinsic lock)或者互斥锁(mutex lock)。这个锁是用来控制对对象的访问的,并且确保在同一时间只有一个线程能够执行具有这个锁的代码块。
在Java中,可以使用synchronized关键字来使用对象的监视器锁。当一个线程进入synchronized代码块时,它会尝试获取该对象的锁。如果这个锁已经被其他线程占用,则当前线程会被阻塞,直到锁被释放。当线程执行完synchronized代码块后,会释放相应的锁,使其他线程能够获取锁并执行。
每个对象都有一个与之关联的锁的原因在于Java中的并发控制机制。通过给每个对象分配一个独立的锁来实现对对象的访问控制,可以确保对共享资源的操作是互斥的,避免多个线程同时对同一资源进行修改导致数据不一致或者竞态条件的问题。
17.3synchronized的锁升级流程
Synchronized用的锁是存在Java对象头里的MarkWord中,锁升级功能主要依赖MarkWord中锁标志位和释放偏向锁标志位。
- 偏向锁:MarkWord存储的是偏向的线程ID
- 轻量锁:MarkWord存储的是指向线程栈中Lock Record的指针
- 重量锁:MarkWord存储的是指向堆中的monitor对象(系统互斥量指针)

17.4无锁
- 创建无锁示例
public class NoLock {
public static void main(String[] args) {
Object obj = new Object();
// 查看对象内部信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
}查看对象的内部信息:

17.5偏向锁
17.5.1偏向锁概述
偏向锁(biased locking):是Java虚拟机中一种用于优化同步性能的锁机制。它的基本思想是,如果一个对象总是被同一个线程访问,那么就可以将该对象的锁偏向于该线程,从而避免进行不必要的同步操作。
当一个线程第一次访问一个偏向锁对象时,Java虚拟机会将该对象的锁偏向于该线程,并在对象头中的偏向线程ID记录该线程的ID。之后,当该线程再次访问该对象时,Java虚拟机会检查对象头中的线程ID是否与当前线程匹配。如果匹配,则无需进行同步操作;否则,JVM会撤销偏向锁,并恢复到正常的锁状态。
17.5.2偏向锁执行过程
偏向锁的操作不用直接操作系统,不涉及用户态到内核态的转换,不必要直接升级为最高级,我们以一个account对象的“对象头”为例。
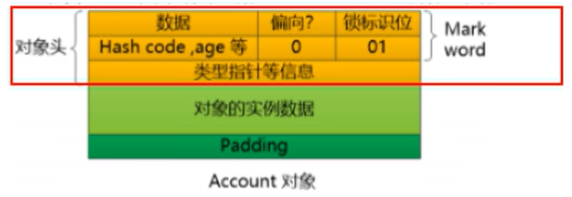
假如有一个线程执行到synchronized代码块的时候,JVM使用CAS操作把线程指针ID记录到Mark Word当中,并修改标偏向标示,标示当前线程就获得该锁。锁对象变成偏向锁(通过CAS修改对象头里的锁标志位),字面意思是“偏向于第-一个获得它的线程”的锁。执行完同步代码块后,线程并不会主动释放偏向锁。

这时线程获得了锁,可以执行同步代码块。当该线程第二次到达同步代码块时会判断此时持有锁的线程是否还是自己(持有锁的线程ID也在对象头里),JVM通过account对象的Mark Word判断:当前线程ID还在,说明还持有着这个对象的锁,就可以继续进入临界区工作。由于之前没有释放锁,这里也就不需要重新加锁。如果自始至终使用锁的线程只有一个,很明显偏向锁几乎没有额外开销,性能极高。
17.5.3偏向锁参数
使用以下命令查看偏向锁参数设置:
java -XX:+PrintFlagsInitial | grep BiasedLock*
开启偏向锁:
-XX:+UseBiasedLocking 关闭延时参数:
-XX:BiasedLockingStartupDelay=0关闭偏向锁:
-XX:-UseBiasedLocking17.5.4偏向锁案例
关闭偏向锁延时,使偏向锁立刻启动生效

public class BasiedLockDemo {
public static void main(String[] args) {
Object obj = new Object();
synchronized (obj) {
// 查看对象内部信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
}
}
17.5.5偏向锁的撤销
当有另外一个线程逐步来竞争锁的时候,就不能再使用偏向锁了,要升级为轻量级锁,使用的是等到竞争出现才释放锁的机制。
竞争线程尝试CAS更新对象头失败,会等到全局安全点(此时不会执行任何代码)撤销偏向锁,同时检查持有偏向锁的线程是否还在执行:
- 第一个线程正在执行
Synchronized方法(处于同步块),它还没有执行完,其他线程来抢夺,该偏向锁会被取消掉并出现锁升级,此时轻量级锁由原来持有偏向锁的线程持有,继续执行同步代码块,而正在竞争的线程会自动进入自旋等待获得该轻量级锁 - 第一个线程执行完
Synchronized(退出同步块),则将对象头设置为无所状态并撤销偏向锁,重新偏向。
- 第一个线程正在执行
17.5.6偏向锁的执行流程
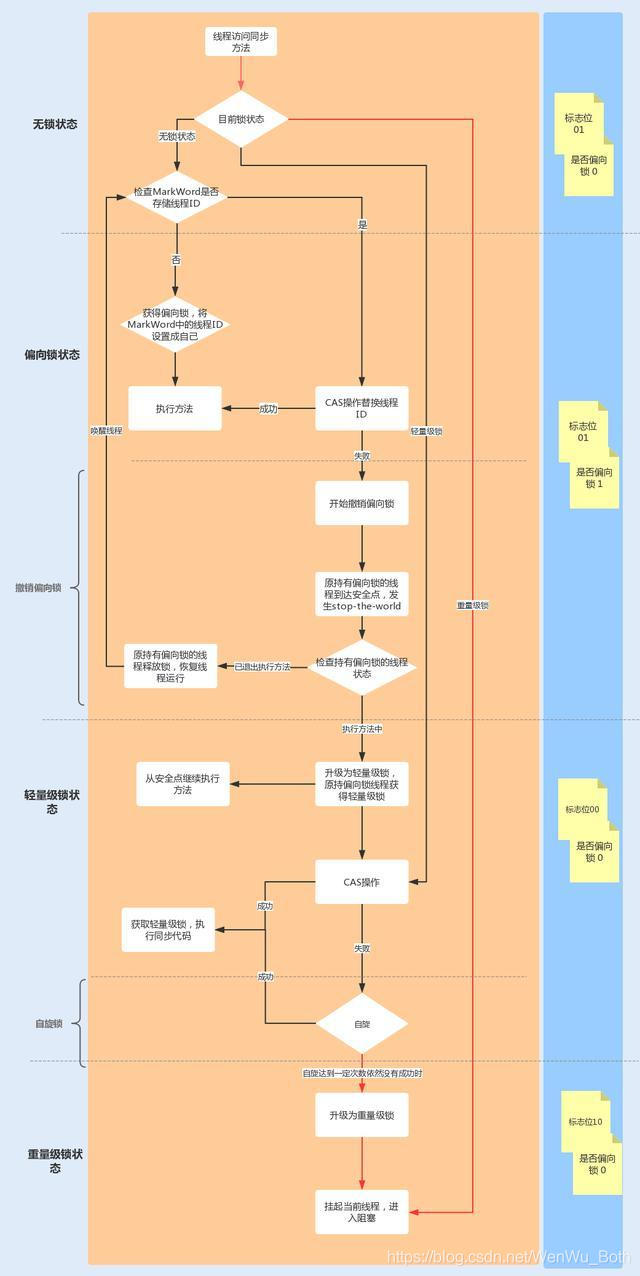
17.5.7偏向锁废弃说明
从Java 15开始,偏向锁(biased locking)逐渐被废弃是因为它的维护成本很高,而且它带来的性能收益已经不再明显。
17.6轻量级锁
17.6.1轻量级锁概述
轻量级锁(lightweight lock)是Java虚拟机中一种用于优化同步性能的锁机制。它的基本思想是,如果一个锁被多个线程交替访问,且不存在竞争,那么就可以使用轻量级锁来避免进行不必要的同步操作。
当一个线程第一次访问一个轻量级锁对象时,Java虚拟机会使用CAS操作(Compare-And-Swap)来尝试获取该对象的锁。如果成功,则该线程将持有该对象的轻量级锁;否则,Java虚拟机会撤销轻量级锁,并转而使用重量级锁。
17.6.2轻量级锁演示
关闭偏向锁,锁对象就可以直接进入轻量级锁。
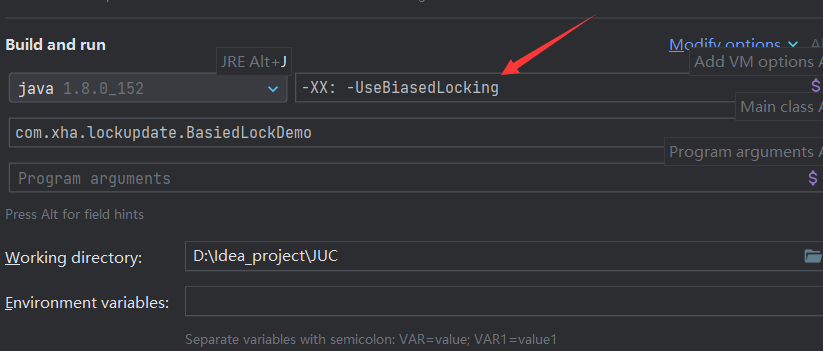
public class BasiedLockDemo {
public static void main(String[] args) {
Object obj = new Object();
synchronized (obj) {
// 查看对象内部信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
}
}

17.6.3偏向锁和轻量级锁的区别
- 偏向锁适用于单线程访问的场景。当一个对象总是被同一个线程访问时,Java虚拟机会将该对象的锁偏向于该线程,从而避免进行不必要的同步操作。当另一个线程尝试访问该对象时,Java虚拟机会撤销偏向锁,并恢复到正常的锁状态。
- 轻量级锁适用于多线程交替访问且不存在竞争的场景。当一个线程第一次访问一个轻量级锁对象时,Java虚拟机会使用CAS操作(Compare-And-Swap)来尝试获取该对象的锁。如果成功,则该线程将持有该对象的轻量级锁;否则,Java虚拟机会撤销轻量级锁,并转而使用重量级锁。
17.7重量级锁
重量级锁(heavyweight lock)是基于管程(monitor)和synchronized关键字来实现的。
在Java中,每个对象都有一个内置的管程(monitor),用于实现线程间的同步和协调。当一个线程进入一个同步方法或同步块时,它会自动获取该对象的锁。如果该锁已经被其他线程持有,则当前线程会被阻塞,直到其他线程释放该锁。当线程离开同步方法或同步块时,它会释放该管程锁,从而允许其他线程进入同步方法或同步块。
重量级锁是管程锁的一种实现方式。当多个线程竞争同一个管程锁时,Java虚拟机会使用重量级锁来实现同步。这种情况下,获取和释放重量级锁需要进行系统调用,这会带来一定的性能开销。
17.8锁升级后hashCode的问题
17.8.1问题概述
当锁升级后,即偏向锁、轻量级锁以及重量级锁后,对象头中并不存储hashCode值,那hashCode值存储在哪里呢?
在Java语言里面一个对象如果计算过哈希码,就应该一直保持该值不变,否则很多依赖对象哈希码的API都可能存在出错风险。而作为绝大多数对象哈希码来源的Object:hashCode0方法,返回的是对象的一致性哈希码(ldentity Hash Code),这个值是能强制保证不变的,它通过在对象头中存储计算结果来保证第一次计算之后,再次调用该方法取到的哈希码值永远不会再发生改变。因此,当一个对象已经计算过一致性哈希码后,它就再也无法进入偏向锁状态了(
直接升级为轻量级锁),而当一个对象当前正处于偏向锁状态,又收到需要计算其一致性哈希码请求时,它的偏向状态会被立即撇销,并且锁会膨胀为重量级锁。在重量级锁的实现中,对象头指向了重量级锁的位置,代表重量级锁的ObjectMonitor类里有字段可以记录非加锁状态(标志位为“01”)下的Mark Word,其中自然可以存储原来的哈希码。
- 在无锁状态下,
Mark Word中可以存储对象的identity hash code值。当对象的hashCode()方法第一次被调用时,JVM会生成对应的identity hash code值并将该值存储到Mark Word中。- 对于偏向锁,在线程获取偏向锁时,会用
Thread ID和epoch值覆盖identity hash code所在的位置。如果一个对象的hashCode()方法已经被调用过一次之后, 这个对象不能被设置偏向锁。因为如果可以的话,那Mark Word中的identity hash code必然会被偏向线程ld给覆盖,这就会造成同一个对象前后两次调用hashCode()方法得到的结果不一致。- 升级为轻量级锁时,JVM会在当前线程的栈帧中创建一个锁记录
(LockRecord)空间,用于存储锁对象的MarkWord拷贝,该拷贝中可以包含identity hash code,所以轻量级锁可以和identity hash code共存,哈希码和GC年龄自然保存在此,释放锁后会将这些信息写回到对象头。- 升级为重量级锁后,
MarkWord保存的重量级锁指针,代表重量级锁的ObjectMonitor类里有字段记录非加锁状态下的MarkWord,锁释放后也会将信息写回到对象头。
17.8.2案例演示
- 当一个对象已经计算过identity hash code,它就无法进入偏向锁状态,跳过偏向锁,直接升级轻量级锁
public class LightweightLockDemo {
public static void main(String[] args) {
Object obj = new Object();
synchronized (obj) {
System.out.println("当前为偏向锁");
// 查看对象内部信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
// 获取到hashCode值
obj.hashCode();
synchronized (obj) {
System.out.println("当前为轻量级锁");
// 查看对象内部信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
}
}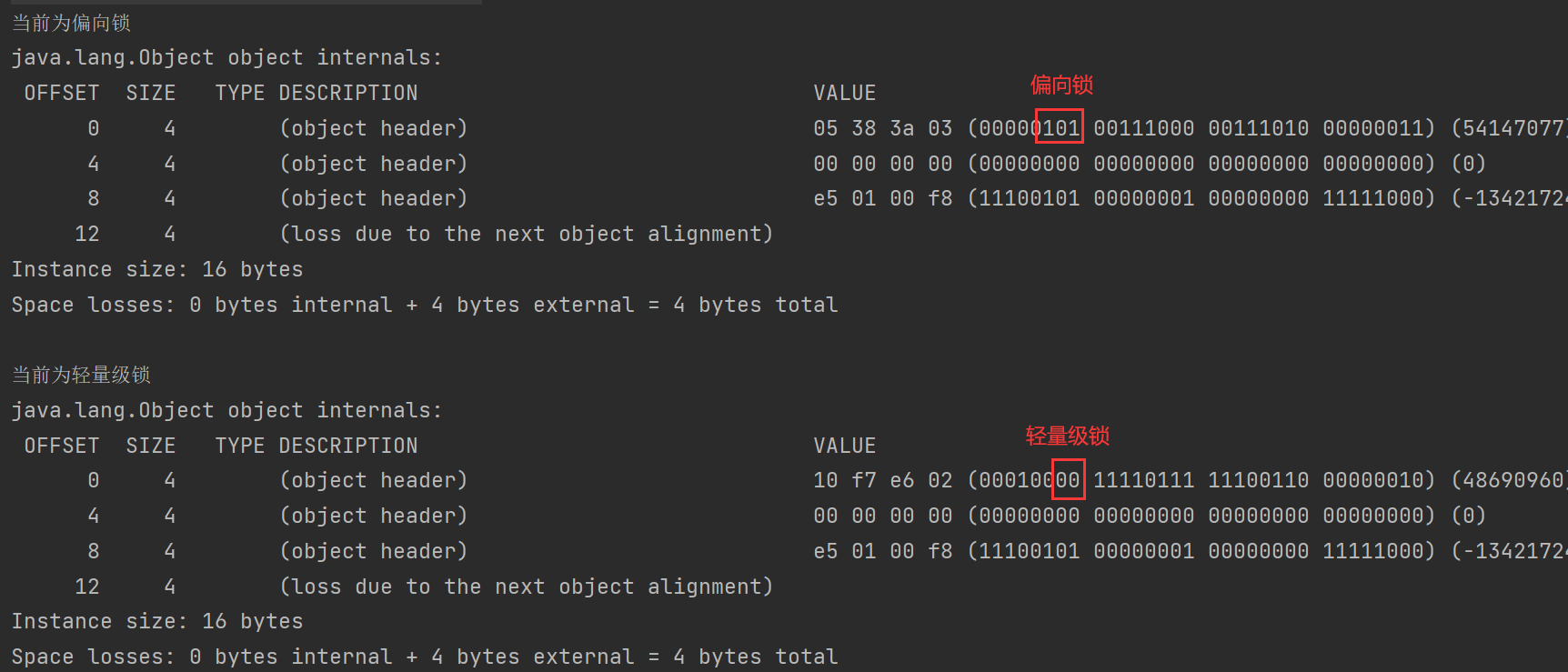
- 偏向锁过程中遇到一致性哈希计算请求,立马撤销偏向模式,膨胀为重量级锁。
public class LightweightLockDemo {
public static void main(String[] args) {
Object obj = new Object();
synchronized (obj) {
System.out.println("当前为偏向锁");
// 查看对象内部信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
// 获取到hashCode值
obj.hashCode();
}
synchronized (obj) {
System.out.println("当前为轻量级锁");
// 查看对象内部信息
System.out.println(ClassLayout.parseInstance(obj).toPrintable());
}
}
}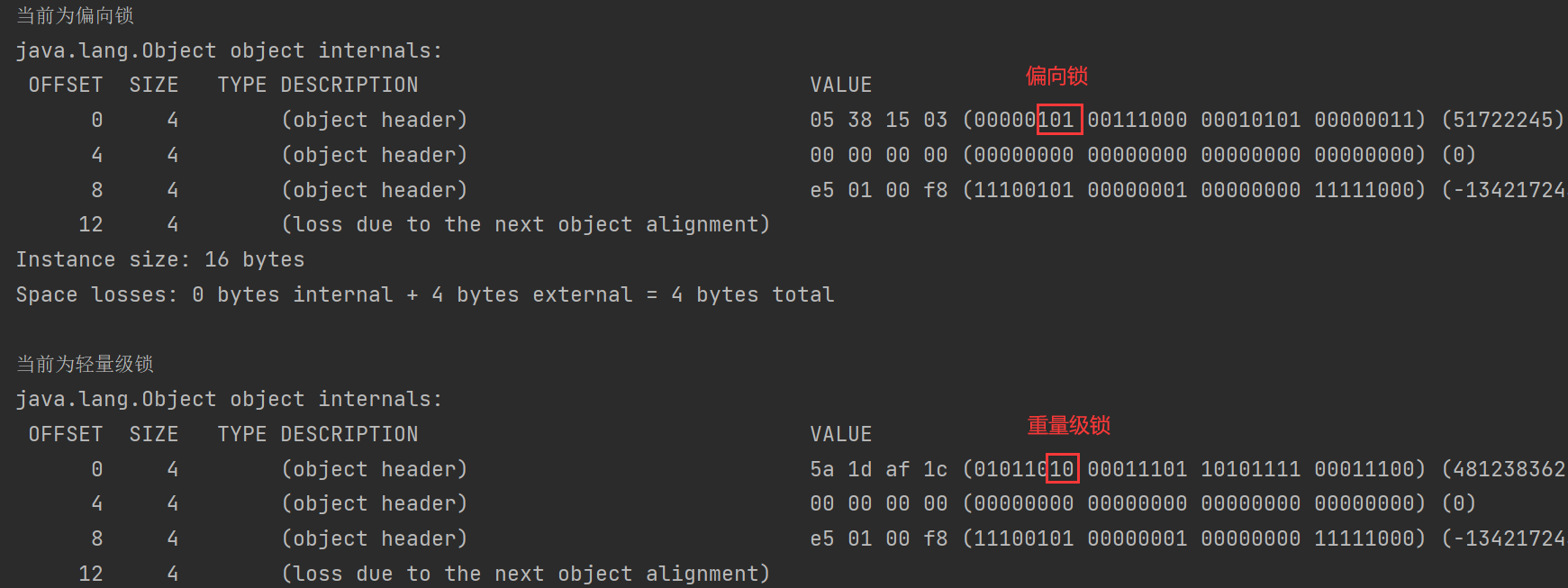
17.9锁的优缺点
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法相比仅存在纳秒级的差距 | 如果线程间存在锁竞争,会带来额外的锁撤销的消耗 | 一个线程访问的同步代码块 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度 | 如果始终得不到锁竞争的线程,使用自旋会消耗CPU | 追求响应时间,同步块执行速度非常快 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗CPU | 线程阻塞,响应时间缓慢 | 追求吞吐量,同步块执行速度较长 |
- 偏向锁:适用于单线程适用的情况,在不存在锁竞争的时候进入同步方法/代码块则使用偏向锁。
- 轻量级锁:适用于竞争较不激烈的情况(这和乐观锁的使用范围类似),存在竞争时升级为轻量级锁,轻量级锁采用的是自旋锁,如果同步方法/代码块执行时间很短的话,采用轻量级锁虽然会占用cpu资源但是相对比使用重量级锁还是更高效。
- 重量级锁:适用于竞争激烈的情况,如果同步方法/代码块执行时间很长,那么使用经量级锁自旋带来的性能消耗就比使用重量级锁更严重,这时候就需要升级为重量级锁。
17.10锁消除
锁消除是Java虚拟机(JVM)中的一种优化技术,它可以在运行时检测到某些锁是不必要的,并将其消除以提高程序性能。这种优化通常发生在即时编译器(JIT)中,它可以分析代码并确定哪些锁是多余的。例如,如果JIT确定一个锁仅被单个线程访问,则该锁可以被消除,因为它不会对程序的正确性产生影响。
如:
/**
* @author Guanghao Wei
* @create 2023-04-14 15:13
* 锁消除
* 从JIT角度看想相当于无视他,synchronized(o)不存在了
* 这个锁对象并没有被共用扩散到其他线程使用
* 极端的说就是根本没有加锁对象的底层机器码,消除了锁的使用
*/
public class LockClearUpDemo {
static Object object = new Object();
public void m1() {
//锁消除问题,JIT会无视它,synchronized(o)每次new出来的,都不存在了,非正常的
Object o = new Object();
synchronized (o) {
System.out.println("-----------hello LockClearUpDemo" + "\t" + o.hashCode() + "\t" + object.hashCode());
}
}
public static void main(String[] args) {
LockClearUpDemo lockClearUpDemo = new LockClearUpDemo();
for (int i = 0; i < 10; i++) {
new Thread(() -> {
lockClearUpDemo.m1();
}, String.valueOf(i)).start();
}
}
}
/**
* -----------hello LockClearUpDemo 229465744 57319765
* -----------hello LockClearUpDemo 219013680 57319765
* -----------hello LockClearUpDemo 1109337020 57319765
* -----------hello LockClearUpDemo 94808467 57319765
* -----------hello LockClearUpDemo 973369600 57319765
* -----------hello LockClearUpDemo 64667370 57319765
* -----------hello LockClearUpDemo 1201983305 57319765
* -----------hello LockClearUpDemo 573110659 57319765
* -----------hello LockClearUpDemo 1863380256 57319765
* -----------hello LockClearUpDemo 1119787251 57319765
*/17.11锁粗化
锁粗化是Java虚拟机(JVM)中的一种优化技术,它可以将多个连续的加锁、解锁操作合并为一个范围更大的加锁、解锁操作,以减少锁操作的开销。例如,如果在循环中对同一个对象进行多次加锁和解锁,JVM可以将这些操作合并为在循环外部对该对象进行一次加锁和解锁。这样可以减少锁操作的次数,从而提高程序性能。
如:
/**
* @author Guanghao Wei
* @create 2023-04-14 15:18
* 锁粗化
* 假如方法中首尾相接,前后相邻的都是同一个锁对象,那JIT编译器会把这几个synchronized块合并为一个大块
* 加粗加大范围,一次申请锁使用即可,避免次次的申请和释放锁,提高了性能
*/
public class LockBigDemo {
static Object objectLock = new Object();
public static void main(String[] args) {
new Thread(() -> {
synchronized (objectLock) {
System.out.println("111111111111");
}
synchronized (objectLock) {
System.out.println("222222222222");
}
synchronized (objectLock) {
System.out.println("333333333333");
}
synchronized (objectLock) {
System.out.println("444444444444");
}
//底层JIT的锁粗化优化
synchronized (objectLock) {
System.out.println("111111111111");
System.out.println("222222222222");
System.out.println("333333333333");
System.out.println("444444444444");
}
}, "t1").start();
}
}18.AQS
18.1AQS概述
AbstractQueuedSynchronizer(AQS)即 抽象队列同步器,其提供了一套可用于实现锁和同步器组件的框架。不夸张地说,AQS是JUC同步框架的基石。AQS通过一个FIFO队列维护线程同步状态,实现类只需要继承该类,并重写指定方法即可实现一套线程同步机制。
AQS根据资源互斥级别提供了独占和共享两种资源访问模式;同时其定义Condition结构提供了wait/signal等待唤醒机制。在JUC中,诸如ReentrantLock、CountDownLatch等都基于AQS实现。
18.2AQS原理
AQS维护了一个volatile int state类型的变量和一个CLH(三个人名缩写)双向队列,队列中的节点持有线程引用,每个节点均可通过getState()、setState()和compareAndSetState()对state进行修改和访问。

当线程获取锁时,即试图对state变量做修改,如修改成功则获取锁;如修改失败则包装为节点挂载到队列中,等待持有锁的线程释放锁并唤醒队列中的节点。
18.3锁和同步器的关系
锁是面向锁的使用者,定义了程序员和锁交互使用层的API,隐藏了实现的细节,直接调用即可。
同步器则是面向锁的实现者,提出统一的规范并简化了锁的实现,将其抽象出来。是一切锁和同步器的实现的公共基础部分。
例如,Java 提供了许多内置的锁,如 synchronized 关键字和 ReentrantLock 类。这些锁都是面向锁的使用者,它们提供了简单易用的 API,使得开发人员能够在代码中使用锁来保护临界区。
而同步器(如 AQS)则是面向锁的实现者。它提供了一种框架,使得开发人员能够更容易地实现自己的锁和同步器。例如,ReentrantLock 类就是基于 AQS 实现的。
18.4AQS内部体系架构
18.4.1AQS体系架构图
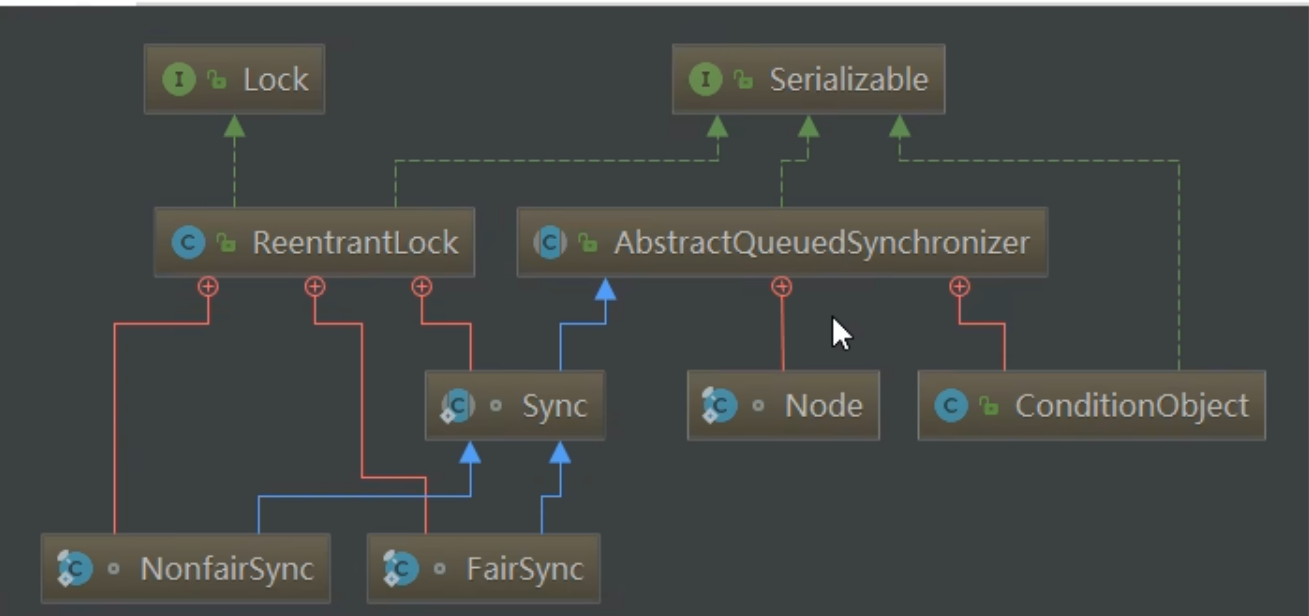
18.4.2AQS内部的成员变量、方法
Node为AbstractQueuedSychronizer的静态内部类。


Node节点:
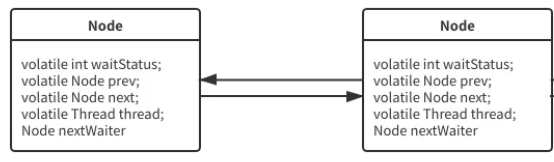
Node主要包含5个核心字段:
waitStatus:当前节点状态,该字段共有5种取值:
CANCELLED = 1。节点引用线程由于等待超时或被打断时的状态。SIGNAL = -1。后继节点线程需要被唤醒时的当前节点状态。当队列中加入后继节点被挂起(block)时,其前驱节点会被设置为SIGNAL状态,表示该节点需要被唤醒。CONDITION = -2。当节点线程进入condition队列时的状态。(见ConditionObject)PROPAGATE = -3。仅在释放共享锁releaseShared时对头节点使用。(见共享锁分析)0。节点初始化时的状态。
prev:前驱节点。
next:后继节点。
thread:引用线程,头节点不包含线程。
nextWaiter:condition条件队列。(见ConditionObject)
18.4.3AQS之ReentrantLock锁原理
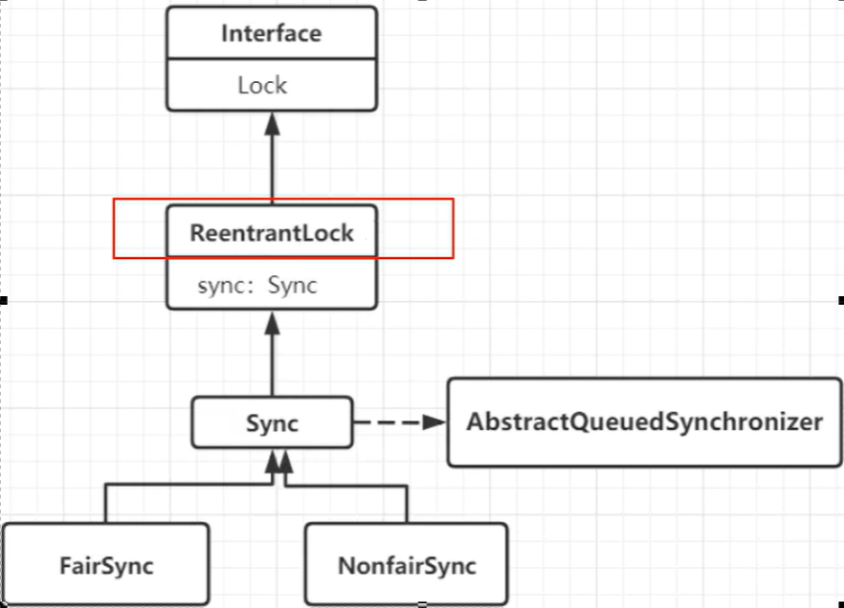
整个ReentrantLock的加锁过程,可以分为三个阶段:
- 尝试加锁;
- 加锁失败,线程入队列;
- 线程入队列后,进入阻塞状态。
ReentrantLock是Lock接口的实现类,其内部有静态内部类Sync,内部类Sync又继承于AbstractQueuedSynchronizer。
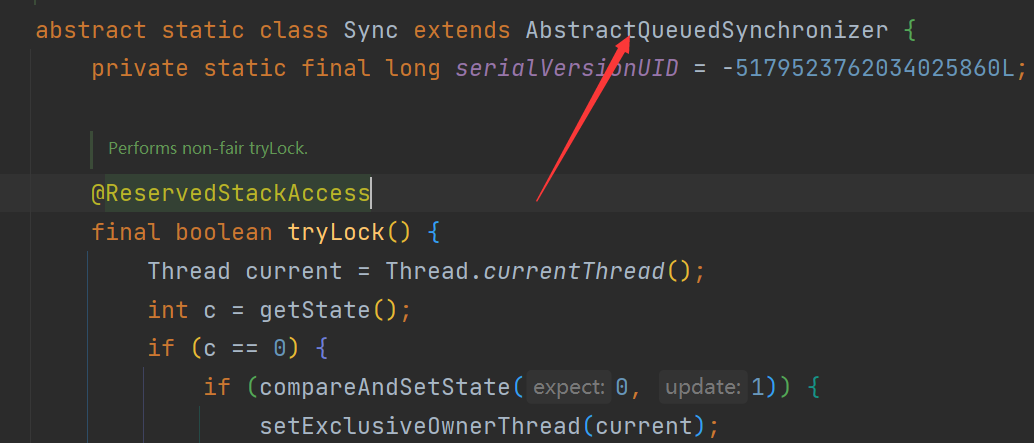
- 当创建一个ReentrantLock,其默认的构造方式实现的是
非公平锁。传入boolean类型的数据来修改公平锁和非公平锁。

- 查看获取到锁,查看
ReentrantLock中lock()的实现方法

ReentrantLock中lock(),查看lock的实现

查看
lock()的实现FairSync
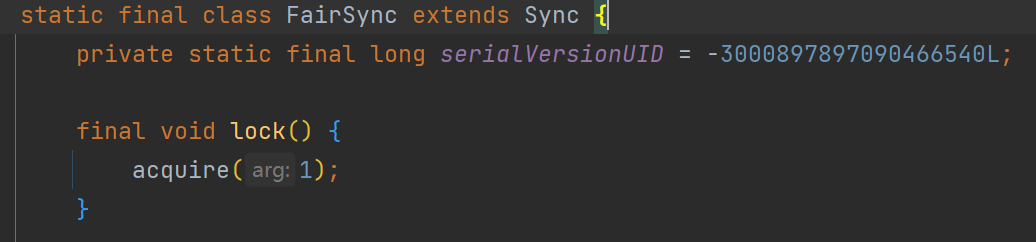
NoFairSync

FairSync和NoFairSync都调用acquire方法
acquire方法是AbstractQueuedSynchronizer当中的方法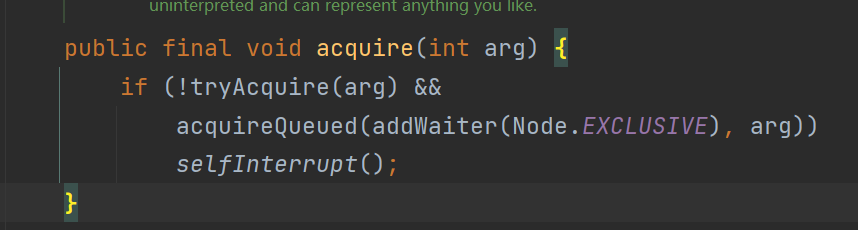
查看
tryAcquire方法,可以发现其是抛出的异常,查看对应的方法实现。


- 查看
FairSync中对应的实现
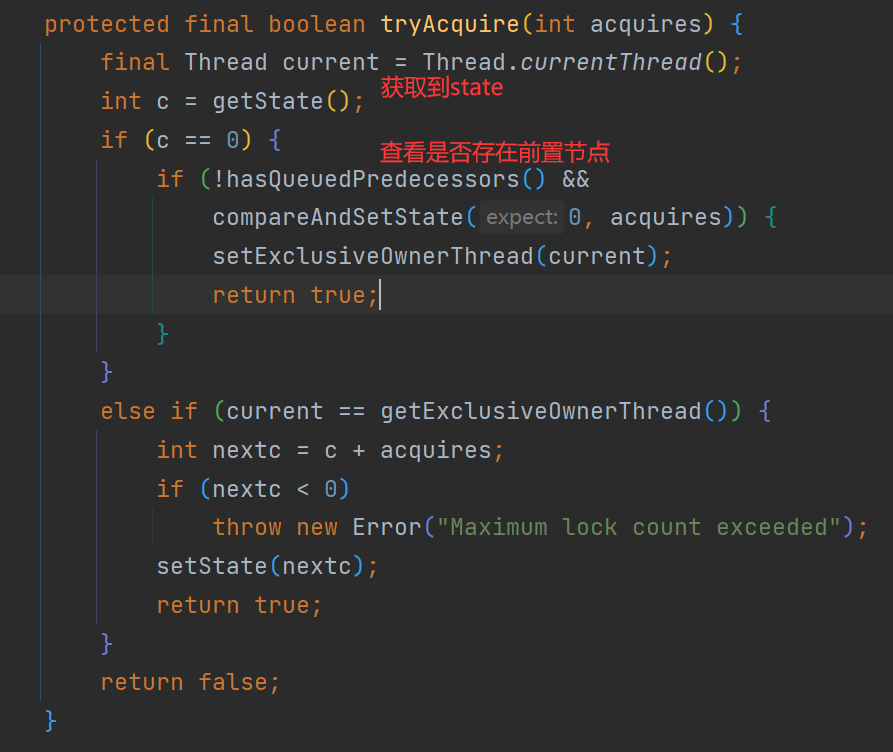
- 查看
NoFairSync中对应的实现

- 总结:
可以明显看出公平锁与非公平锁的lock()方法唯一的区别就在于公平锁在获取同步状态时多了一个限制条件:hasQueuedPredecessors(),hasQueuedPredecessors是公平锁加锁时判断等待队列中是否存在有效节点的方法
公平锁:
公平锁保证线程按照请求的顺序获取锁。当多个线程同时请求获取锁时,公平锁会维护一个等待队列,新到来的线程会排队等待,先请求的线程先获取锁。公平锁的优点是保证了锁的公平性,避免了饥饿现象(即某个线程一直无法获取锁),但它可能会导致线程切换的开销增加,降低了并发性能。
非公平锁:
非公平锁允许新请求的线程比等待队列中的线程优先获取锁。当一个线程释放锁时,不一定是等待时间最长的线程获取锁,而是新到来的线程有机会直接获取锁。非公平锁的优点是减少了线程切换的开销,提高了并发性能,但它可能导致等待时间长的线程一直无法获取锁,存在不公平性。
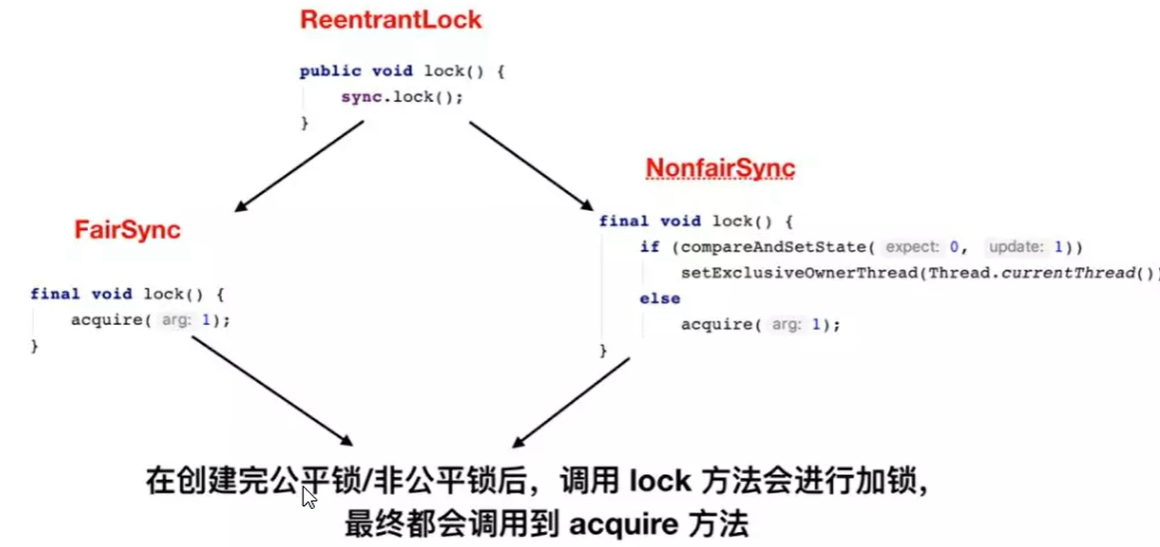
18.4.4acquire方法解析
acquire核心为tryAcquire、addWaiter和acquireQueued三个函数,其中tryAcquire需具体类实现。 每当线程调用acquire时都首先会调用tryAcquire,失败后才会挂载到队列,因此acquire实现默认为非公平锁。
.jpg)
在创建完公平锁/非公平锁之后,调用lock()进行加锁,最终都会调用acqiure方法。
FairSync
NoFairSync
FairSync和NoFairSync都调用acquire方法
public final void acquire(int arg) {
// tryAcquire需实现类处理
// 如获取资源成功,直接返回
if (!tryAcquire(arg) &&
// 如获取资源失败,将线程包装为Node添加到队列中阻塞等待
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
// 如阻塞线程被打断
selfInterrupt();
}
- tryAcquire()方法
tryAcquire()方法用于尝试获取到锁
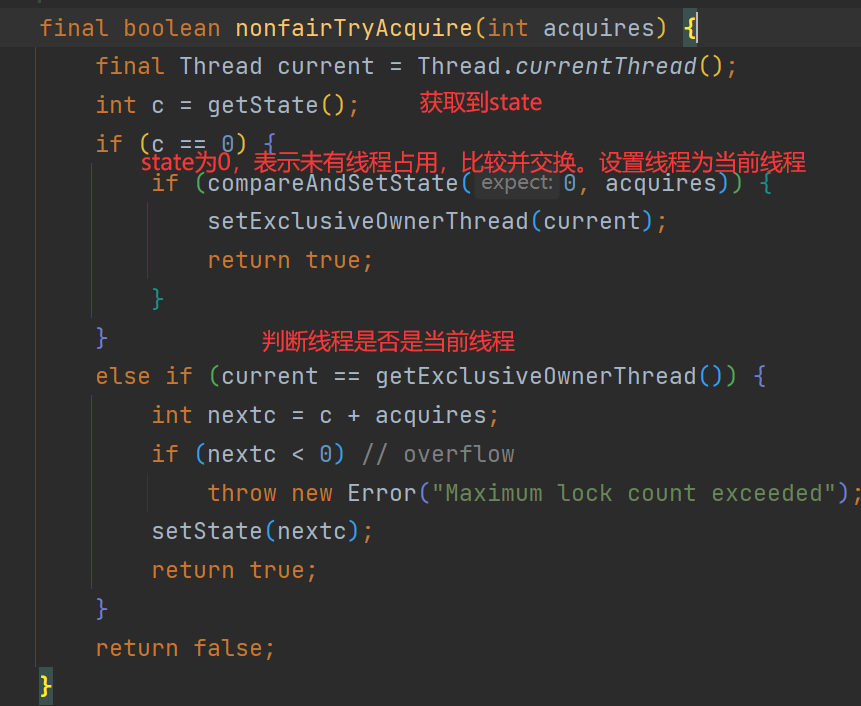
tryAcquire失败后才会挂载到队列,addWaiter将线程包装为独占节点,尾插式加入到队列中,如队列为空,则会添加一个空的头节点。值得注意的是addWaiter中的enq方法,通过CAS+自旋的方式处理尾节点添加冲突。
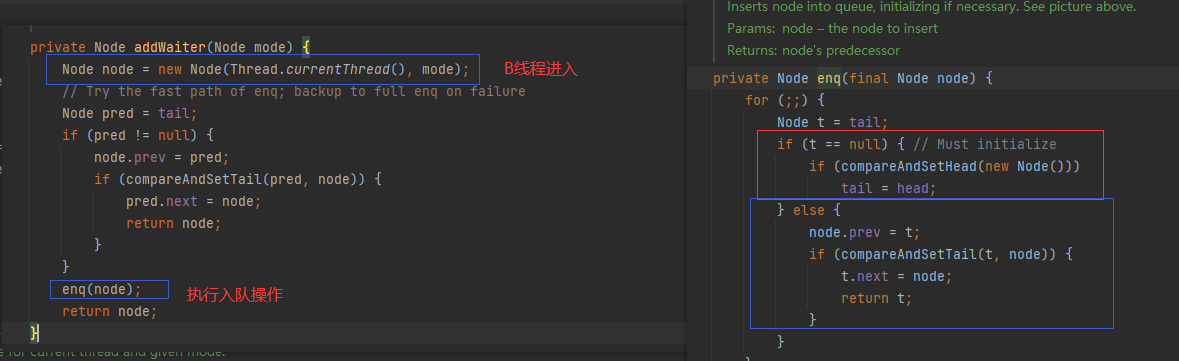
在双向链表中,第一个节点为虚节点(也叫做哨兵节点),其实不存储任何信息,只是占位。真正的第一个有数据的节点,是从第二个节点开始的
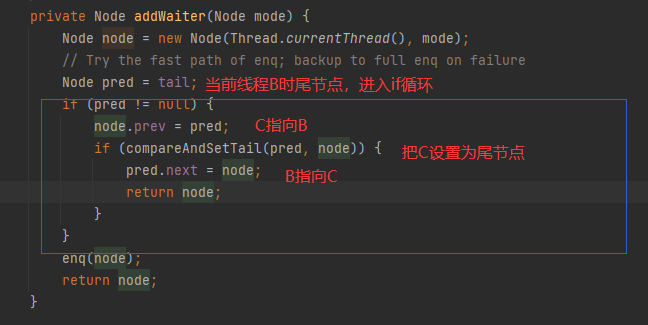
acquireQueue在线程节点加入队列后判断是否可再次尝试获取资源,如不能获取则将其前驱节点标志为SIGNAL状态(表示其需要被unpark唤醒)后,则通过park进入阻塞状态。

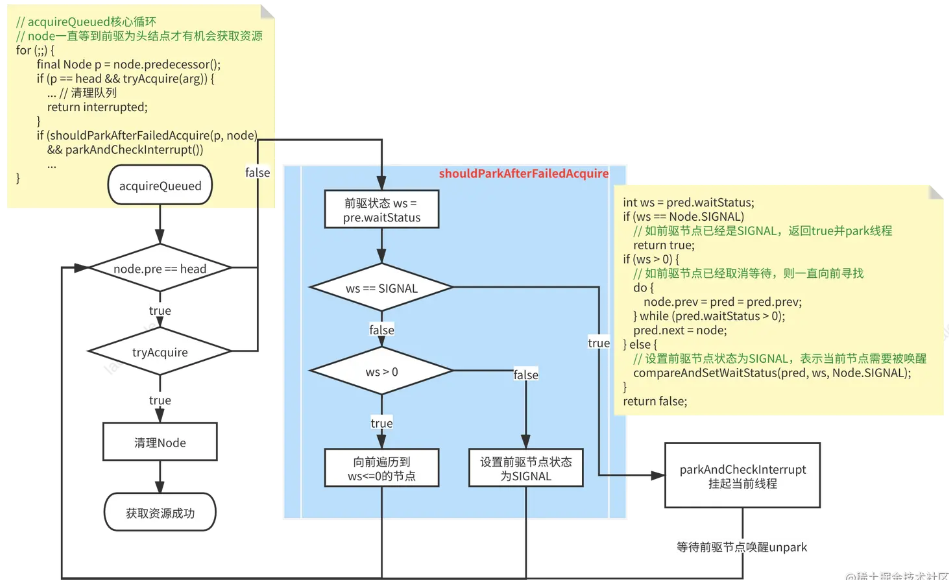
参照流程图,acquireQueued方法核心逻辑为for(;;)和shouldParkAfterFailedAcquire。tail节点默认初始状态为0,当新节点被挂载到队列后,将其前驱即原tail节点状态设为SIGNAL,表示该节点需要被唤醒,返回true后即被park陷入阻塞。for循环直到节点前驱为head后才尝试进行资源获取。
13. ReentrantLock、ReentrantReadWriteLock、StampedLock讲解
13.1 关于锁的面试题
- 你知道Java里面有那些锁
- 你说说你用过的锁,锁饥饿问题是什么?
- 有没有比读写锁更快的锁
- StampedLock知道吗?(邮戳锁/票据锁)
- ReentrantReadWriteLock有锁降级机制,你知道吗?
13.2 简单聊聊ReentrantReadWriteLock
13.2.1 概念
读写锁说明
- 一个资源能够被多个读线程访问,或者被一个写线程访问,但是不能同时存在读写线程
再说说演变
- 无锁无序->加锁->读写锁->邮戳锁
读写锁意义和特点
- 它只允许读读共存,而读写和写写依然是互斥的,大多实际场景是”读/读“线程间不存在互斥关系,只有”读/写“线程或者”写/写“线程间的操作是需要互斥的,因此引入了 ReentrantReadWriteLock
- 一个ReentrantReadWriteLock同时只能存在一个写锁但是可以存在多个读锁,但是不能同时存在写锁和读锁,也即资源可以被多个读操作访问,或一个写操作访问,但两者不能同时进行。
- 只有在读多写少情景之下,读写锁才具有较高的性能体现。
13.2.2 特点
可重入
读写兼顾
结论:一体两面,读写互斥,读读共享,读没有完成的时候其他线程写锁无法获得
锁降级:
- 将写锁降级为读锁——>遵循获取写锁、获取读锁再释放写锁的次序,写锁能够降级为读锁
- 如果一个线程持有了写锁,在没有释放写锁的情况下,它还可以继续获得读锁。这就是写锁的降级,降级成为了读锁。
- 如果释放了写锁,那么就完全转换为读锁
- 如果有线程在读,那么写线程是无法获取写锁的,是悲观锁的策略
13.3锁降级
13.3.1概念
读写锁的锁降级指的是写锁降级成为了读锁
当一个线程获取了写锁,并且又获取了读锁(获取写锁的线程可以获取读锁),那么当该线程释放了写锁时,该线程拥有的锁就会进行降级,变为了读锁。
13.3.2锁降级目的
锁降级的目的是为了保证数据的可见性。如果当前线程不获取读锁而是直接释放写锁,那么另一个线程可能会获取写锁并修改数据,而当前线程无法感知这些更改。但是,如果当前线程遵循锁降级的步骤并获取读锁,则其他试图获取写锁的线程将被阻塞,直到当前线程使用数据并释放读锁之后,其他线程才能获取写锁进行数据更新。
一般我们用锁进行操作数据时,都是下面三步
- 获取锁
- 操作数据
- 释放锁
假如一个线程对某个数据进行先写后读操作,那么操作顺序一般变成下面所示
- 获取写锁
- 修改数据
- 释放写锁
- 获取读锁
- 访问数据
- 释放读锁
那么此时问题就出来了,在该线程释放写锁的一瞬间,就会有其他线程去获取写锁,那么该线程就会获取读锁失败,并且在线程在等待自旋获取读锁中,那么,当其他线程修改完数据并且释放了写锁,该线程再去获取读锁进行访问,就会出现无法感知其他线程对数据的修改状况出现
比如说,线程A获取写锁将变量修改成了5,然后释放了写锁,其他线程去获取写锁将变量修改成了6,线程A再获取了读锁进行访问变量,得到的结果为6,出现了幻觉一样,这就是没有感知到其他线程对数据修改,也就是幻读。
所以,建议是获取了写锁之后,假如后续还要对数据进行访问,一定要获取读锁再释放写锁,拿到的读锁会限制写锁的获取。
其中,写锁能够降级为读锁。但是读锁不能升级为写锁。

13.4 邮戳锁StampedLock
13.4.1 是什么?
StampedLock是JDK1.8中新增的一个读写锁,也是对JDK1.5中的读写锁ReentrantReadWriteLock的优化
stamp 代表了锁的状态(long类型)。当stamp返回零时,表示线程获取锁失败,并且当释放锁或者转换锁的时候,都要传入最初获取的stamp值。
13.4.2 它是由饥饿问题引出
锁饥饿问题:
- ReentrantReadWriteLock实现了读写分离,但是一旦读操作比较多的时候,想要获取写锁就变得比较困难了,因此当前有可能会一直存在读锁,而无法获得写锁。
如何解决锁饥饿问题:
- 使用”公平“策略可以一定程度上缓解这个问题
- 使用”公平“策略是以牺牲系统吞吐量为代价的
- StampedLock类的乐观读锁方式—>采取乐观获取锁,其他线程尝试获取写锁时不会被阻塞,在获取乐观读锁后,还需要对结果进行校验
13.4.3 StampedLock的特点
- 所有获取锁的方法,都返回一个邮戳,
stamp为零表示失败,其余都表示成功 - 所有释放锁的方法,都需要一个邮戳,这个
stamp必须是和成功获取锁时得到的stamp一致 StampedLock是不可重入的,危险(如果一个线程已经持有了写锁,在去获取写锁的话会造成死锁)- 读的过程中也允许写锁介入
StampedLock有三种访问模式:
- Reading(读模式悲观):功能和ReentrantReadWriteLock的读锁类似
- Writing(写模式):功能和ReentrantReadWriteLock的写锁类似
- Optimistic reading(乐观读模式):无锁机制,类似与数据库中的乐观锁,支持读写并发,很乐观认为读时没人修改,假如被修改在实现升级为悲观读模式